.png) STMCU小助手
发布时间:2021-12-19 15:00
STMCU小助手
发布时间:2021-12-19 15:00
|
移植一些算法到STM32上,算法在PC上能够运行,而移植到STM32的时候就会出现问题,' J6 D) m* N( k i9 l $ ~( j1 w0 r' U( a1 V1 k: G6 ] 总结来说主要是因为编译器的版本不同,MDK5的编译器是很古老的编译器,有些C语法会有问题。 
& O. ~1 Z8 F4 L. E6 y8 ^ 常见的问题就是:( H% \& L" j. {0 ^8 [ 9 P$ J7 d0 j6 K% `+ } 1.结构体赋值的时候,在32里面的代码,结构体赋值必须要一个变量一个变量的赋值,不能够直接赋值。 2.定义变量的时候不能用的时候才定义变量,需要将变量放在这个模块的前面3 n$ H- |5 i) W 将算法移植到STM32的时候,首先要考虑的就是STM32的内存大小是否足够大,如果不够大,一般就是报有.ANY的一些错误。(所以建议一开始移植算法的时候使用比较好的硬件条件来移植,不然后面出了问题可能都不知道到底在哪里出错了), F+ E. Z' |( b 如果定义的数组太大,超出了STM32堆栈的大小,那么STM32就会进入Hardfault。(因为进入Hardfault会有延时一行代码,所以建议查看Hardfault的时候建议使用上一盘中JTAG调试窗口中查看中断的窗口,能够更明白的清除Hardfault在哪里产生的) 
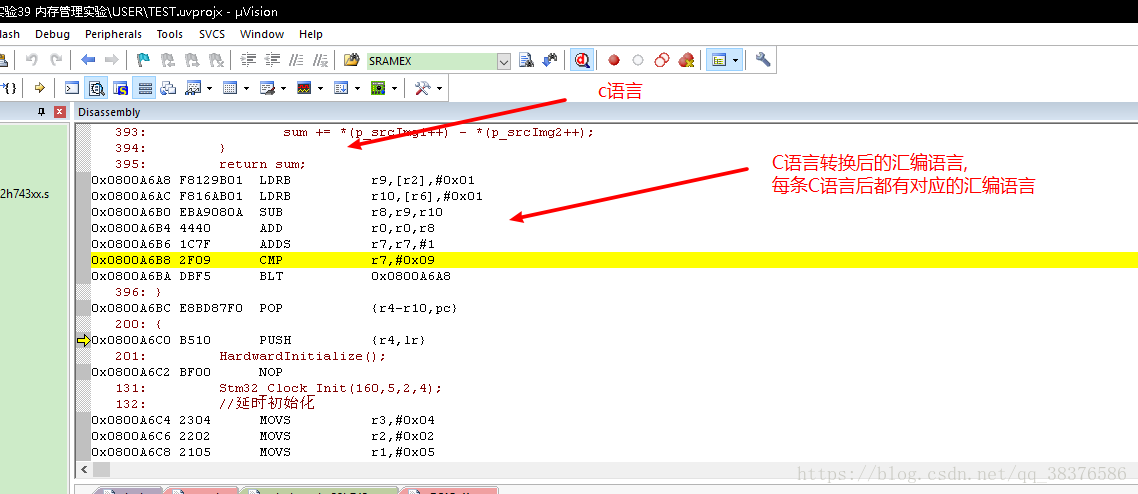
调试算法一定要善用汇编语言,用汇编语言看C语言的本质. 
移植算法的时候也经常需要使用动态内存分配,STM32自带的SRAM又很小,很难满足算法需要的SRAM要求,所以需要在32中外扩SRAM芯片。既然需要动态内存分配,自然也就需要内存管理了。在STM32中c语言标准动态内存分配的关键字malloc也就没这么好用了,最好就是要使用正点原子的内存管理使用,用它提供的分配函数来进行内存的分配与管理。 好了,说了这么多,终于说到了标题的内存了,在调试内存管理的时候,为了防止有申请的内存溢出堆栈的大小,因此在申请的时候最好每一步都调用一次的内存使用率函数查看一下现在内存占用率。防止堆栈溢出。而且在运行的时候,最好能够清楚的了解到这个分配程序是在哪一个文件的哪一行,这样能够方便我们的调试。+ V+ B: n7 r0 Z5 Y$ P! J 这个函数的演示效果:+ j2 g& o0 V/ C w- W 
3 B8 p U, L m, l- f1 k& H0 W 分享一下H7将内存使用率和获取到这个函数在哪一行上传到串口的函数。(即实现上面效果的函数)) u+ F( @, p% L) l. i+ o) ^" I % E2 R8 x/ t& ]8 S- R9 h" Q7 ~ .c文件中的上传代码: ! o8 K6 {' e, l) A1 M/ v
在.h中需要添加的一个宏定义。
5 m. P! N8 _$ E+ H `3 H- k0 Q 获取到文件名和行数不单单只可以在内存管理函数中使用,也可以看你个人的需求移植到其他的地方。 . v- C- `) s$ h1 C, x" C% z |
【经验分享】STM32_H7_ADC
STM32H7R/S高性能MCU:安全性,大存储和优异图显赋能更多应用创新
Stm32H7XX GCC下分散加载实现
【银杏科技ARM+FPGA双核心应用】STM32H7系列10——ADC
DIY-STM32H750核心板
[nucleo-H7A3ZI-Q]1-点亮一个皮皮灯
DIY-STM32H743核心板
【银杏科技ARM+FPGA双核心应用】STM32H7系列57——MDK_FLM
1月10日有奖直播 | 基于STM32 的CODESYS智能自动化解决方案
STM32的CAN FD位定时设置注意事项