.png) STMCU小助手
发布时间:2021-11-20 23:00
STMCU小助手
发布时间:2021-11-20 23:00
|
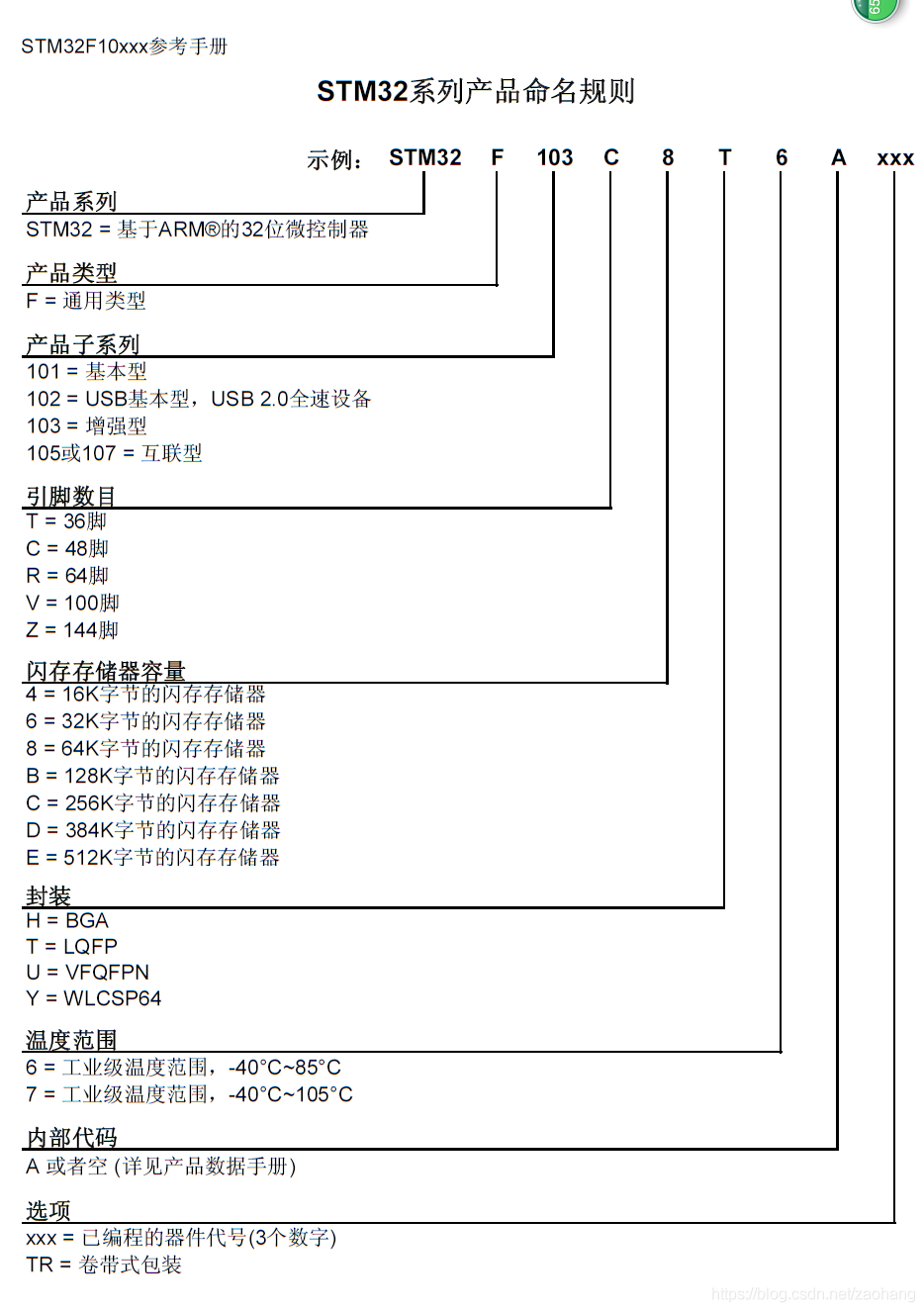
1、F0属于Cortex-M0,F1属于Cortex-M3,F4属于Cortex-M4 Cortex-M分为:M0,M0+,M3,M4,M7 M0,M0+:基础版本,有过于基础,所以生产不出来高性能的STM32的单片机,功耗比较低 M3:目前最主流的设计内核选型,应用范围广; M4:比较着M3的内核来说,M4处理器添加了DSP的数据(这里可以认为是浮点数)处理的指令;重点解释一下:对于CPU(不是SOC)来说,运算浮点类型的数据是很麻烦的一件事,在选型的时候,如若用应用的领域需要大量浮点数据的运算的时候,那么就要选择M4的内核,M4会大大提高处理器性能和运算速度,而如果要要处理的浮点数据不多,则可以直接选择M3内核处理器;比如项目是平衡车或者平衡器的时候选择M4比较好; M7:性能好和功耗高兼具,适合追求极致性能项目; 可以认为:数字越大,性能越高; ———————————————— 1、为什么选择Cortex-M0 能耗最低的最小 ARM 处理器 Cortex-M0 的代码密度和能效优势意味着它是各种应用中 8/16 位设备的自然高性价比换代产品,同时保留与功能丰富的 Cortex-M3 处理器的工具和二进制向上兼容性。 超低的能耗 Cortex-M0 处理器在不到 12 K 门的面积内能耗仅有 85 µW/MHz(0.085 毫瓦),所凭借的是作为低能耗技术的领导者和创建超低能耗设备的主要推动者的无与伦比的 ARM 专门技术。 简单 指令只有 56 个,这样您便可以快速掌握整个 Cortex-M0 指令集(如果需要);但其 C 语言友好体系结构意味着这并不是必需的。可供选择的具有完全确定性的指令和中断计时使得计算响应时间十分容易。 优化的连接性 设计为支持低能耗连接,如 Bluetooth Low Energy (BLE)、IEEE 802.15 和 Z-wave,特别是在这样的模拟设备中:这些模拟设备正在增加其数字功能,以有效地预处理和传输数据。 2、为什么选择Cortex-M3 提供更高的性能和更丰富的功能 于 2004 年引进、最近通过新技术进行了更新并更新了可配置性的 Cortex-M3,是专门针对微控制器应用开发的主流 ARM 处理器。 性能和能效 具有高性能和低动态能耗,Cortex-M3 处理器提供领先的功效:在 90nmG 基础上为 12.5 DMIPS/mW。将集成的睡眠模式与可选的状态保留功能相结合,Cortex-M3处理器确保对于同时需要低能耗和出色性能的应用不存在折衷。 全功能 该处理器执行 Thumb®-2 指令集以获得最佳性能和代码大小,包括硬件除法、单周期乘法和位字段操作。Cortex-M3 NVIC 在设计时是高度可配置的,最多可提供 240 个具有单独优先级、动态重设优先级功能和集成系统时钟的系统中断。 丰富的连接 功能和性能的组合使基于 Cortex-M3 的设备可以有效处理多个 I/O 通道和协议标准,如 USB OTG (On-The-Go)。 3、为什么选择Cortex-M4 目标用用:专门面向电动机控制、汽车、电源管理、嵌入式音频和工业自动化市场的新兴类别的灵活解决方案。 曾获大奖的高能效数字信号控制 Cortex-M4 提供了无可比拟的功能,以将 32 位控制与领先的数字信号处理技术集成来满足需要很高能效级别的市场。 易于使用的技术 Cortex-M4 通过一系列出色的软件工具和 Cortex 微控制器软件接口标准 (CMSIS)使信号处理算法开发变得十分容易。 三、规范 1、M0 ARM Cortex-M0 处理器执行 Thumb 指令集,包括少量使用Thumb-2 技术的32 位指令。这是ARM Cortex-M3 和ARM Cortex-M4 支持的指令集的二进制向上可兼容子集。 2、M3 内核面积、频率范围和功耗取决于工艺、库和优化。上面引用的数字是使用通用 TSMC 工艺技术和 ARM 物理 IP 标准单元库和 RAM 的合成核心的说明。面积数字包括 CM3Core、嵌套向量中断控制器 (NVIC) 和总线矩阵,但不包括可选组件(包括内存保护单元、嵌入式跟踪宏单元、断点单元、数据检测点单元和跟踪端口接口单元)。 速度优化的实现是指为了实现目标频率性能而做出的库选择、合成流决策和折衷。面积优化的实现是指为了实现目标面积密度而做出的库选择、合成流决策和折衷。 3、M4 内核面积、频率范围和功耗取决于工艺、库和优化。上面引用的数字是使用低功耗工艺技术和 ARM 物理 IP 标准单元库和 RAM 的合成内核的说明。面积数字包括中央内核(包括 DSP 扩展、嵌套矢量中断控制器 (NVIC) 和总线矩阵),但不包括可选组件(包括内存保护单元、嵌入式跟踪宏单元、断点单元、数据检测点单元和 TracePort Interface Unit。 速度优化的实现是指为了实现目标频率性能而做出的库选择、合成流决策和折衷。面积优化的实现是指为了实现目标面积密度而做出的库选择、合成流决策和折衷。 以下的一点为M4页面特有的介绍: 系统 IP 系统 IP 组件对于在芯片上构建复杂的系统至关重要,通过利用系统 IP 组件,开发人员可以显著缩短开发和验证周期,从而节省成本并缩短产品的上市时间。 意法半导体: 1、 STM32 F0xx系列(M0 48MHZ) 2、 STM32 Lxxx系列(M3 32MHZ) 3、 STM32 F1xx系列(M3 72MHZ) 4、 STM32 F2xx系列(M3 120MHZ) 5、 STM32 F3xx系列(M3 120MHZ)?? 6、 STM32 F4xx系列(M4 168MHZ) 
|
 微信公众号
微信公众号
 手机版
手机版