.png) STMCU小助手
发布时间:2021-12-7 11:00
STMCU小助手
发布时间:2021-12-7 11:00
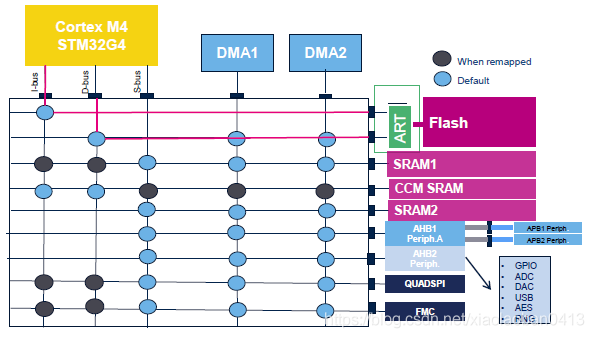
1.ART加速
ART在Flash之前,ART加速可以提高Flash的读取运行速度。 ➢ 程序实现(任选一种): 1,使用库函数(HAL): __HAL_FLASH_INSTRUCTION_CACHE_ENABLE(); __HAL_FLASH_DATA_CACHE_ENABLE(); 2,寄存器操作: FLASH->ACR |= (1<<9);//将第9位置1 FLASH->ACR |= (1<<10);//将第10位置1 
如果要将时钟跑到170MHz,需要设置到Rang1 Boost模式 2.CCM SRAM 
CCM SRAM直接连接到 I-Bus ,D-Bus中,可以提升关键代码的速度,建议可以将关键代码放在这个区域。 3.CoreMark测试 • CoreMark是一项测试处理器性能的基准测试 • 代码使用C语言写成,包含:列举,数学矩阵操作和状态及CRC等运算法则 • 目前CoreMark已迅速成为测量与比较处理器性能的业界标准基准测试 • CoreMark的得分越高,意味着性能更高 • CoreMark官网的连接地址:http://www.eembc.org/coremark/index.php。 

比较处理器的时候,不要单看主频,还需要了解综合的实力,有的处理器主频虽高,但是没有太大的用。 4.浮点运算 能提高运算精度,减少运算转化之间的损失,做算法类的项目需要用到的比较多。 
注意:除法和开方的运算周期过长,如无必要,尽量不要用,尽量将其转化为运算周期较少的加减乘运算 
浮点运算实例: 一般需要在运算结果前写上(float)或者标注f,否则一律认为其为双精度,将会大大增加运算的时间。 浮点运算-FIR(滤波运算) 在这里插入图片描述 

先看内核再看主频,才能判断效率,比如F1和F3都是72M的主频,可是F3是M3的内核,比M1的FIR运算快了7倍!!!! |
STM32G47x 双 Bank 模式下在线升级
DMA 原理从 0 到 1:为什么它能解放 CPU?一文讲透 DMA 的工作流程
【经验分享】STM32G4之基本定时器
NUCLEO-G474RE 扩展 LSM6DSO 传感器数据融合实操演示全解析
经验分享 | STM32G474 高精度定时器同步功能全解析 从内部互联到多芯片协同的实现方案
经验分享 | STM32G4双BANK启动应用演示
STM32G4 LPTIM+DMAMUX 实现并行输出应用示例
实战经验 | LAT1578 SAU对NSC分区的影响
经验分享 | STM32G474 HRTIM Triggered-half模式实现两相交错电源180°相位同步方案
STM32大神笔记,超详细单片机学习汇总资料
 微信公众号
微信公众号
 手机版
手机版