.png) STMCU小助手
发布时间:2022-1-5 21:11
STMCU小助手
发布时间:2022-1-5 21:11
|
01 前言 为什么可以在STM32上面跑神经网络?简而言之就是使用STM32CubeMX中的X-Cube-AI扩展包将当前比较热门的AI框架进行C代码的转化,以支持在嵌入式设备上使用。目前使用X-Cube-AI需要在STM32CubeMX版本5.0以上,支持转化的模型有Keras、TFlite、ONNX、Lasagne、Caffe、ConvNetJS。 Cube-AI把模型转化为一堆数组,而后将这些数组内容解析成模型,和Tensorflow里的模型转数组后使用原理是一样的。 一、环境安装和配置
02 AI神经网络模型搭建 这里使用官方提供的模型进行测试,用keras框架训练:![J7)_F]}QX`@W2`[U4WB2%QV.png](data/attachment/forum/202201/02/231753i7cdnr4pzpfpczm0.png "J7)_F]}QX`@W2`[U4WB2%QV.png")
2.1 模型介绍 在Keras中使用CNN进行人类活动识别:此存储库包含小型项目的代码。该项目的目的是创建一个简单的基于卷积神经网络(CNN)的人类活动识别(HAR)系统。该系统使用来自3D加速度计的传感器数据,并识别用户的活动。 例如:前进或后退。HAR意为Human Activity Recognition(HAR)system,即人类行为识别。 这个模型是根据人一段时间内的3D加速度数据,来判断人当前的行为,比如走路,跑步,上楼,下楼等,很符合Cortex-M系列MCU的应用场景。使用的数据如下图所示。 
存储库包含以下文件
03 新建工程 1. 这里默认大家都已经安装好了STM32CubeMX软件。在STM32上验证神经网络模型(HAR人体活动识别),一般需要STM32F3/F4/L4/F7/L7系列高性能单片机,运行网络模型一般需要3MB以上的闪存空间,一般的单片机不支持这么大的空间。CUBEMX提供了一个压缩率的选项,可以选择合适的压缩率,实际是压缩神经网络模型的权重系数,使得网络模型可以在单片机上运行,压缩率为8,使得模型缩小到366KB,验证可以通过; 
然后按照下面的步骤安装好CUBE.AI的扩展包 G5.png")
这个我安装了三个,安装最新版本的一个版本就可以。 
接下来就是熟悉得新建工程了 ![KX0VC~__G@{[)]MM6(BKRUT.png](data/attachment/forum/202201/02/231750w661ly76926xa76z.png "KX0VC~__G@{[)]MM6(BKRUT.png")
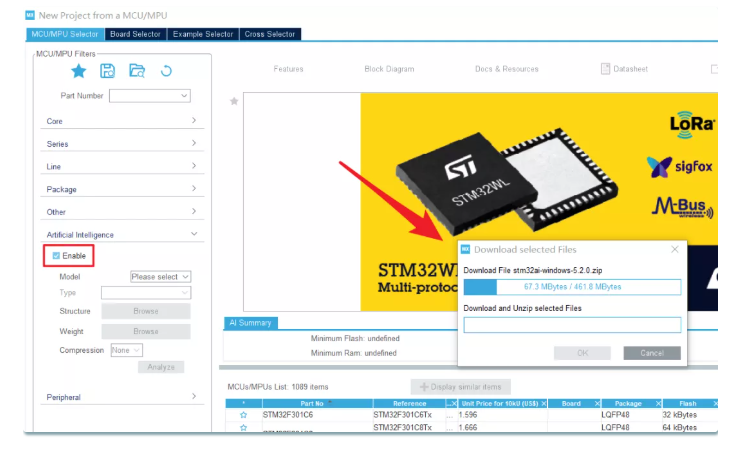
因为安装了AI的包,所以在这个界面会出现artificial intelligence这个选项,点击Enable可以查看哪一些芯片支持AI 
接下来就是配置下载接口和外部晶振了。 
![`TNJH1~FRE[W5QLQ$RO]KRE.png](data/attachment/forum/202201/02/231749j4995uz45ua8gez4.png "`TNJH1~FRE[W5QLQ$RO]KRE.png")
然后记得要选择一个串口作为调试信息打印输出。 7.png")
选择Software Packs,进入后把AI相关的两个包点开,第一个打上勾,第一个选择Validation。 ![%C_P`2HW{D1Z2I}}46}R]DC.png](data/attachment/forum/202201/02/231748w888il1fn0pjj50o.png "%C_P`2HW{D1Z2I}}46}R]DC.png")
![OPIDCC]JV]EQP1`9_SDJT%O.png](data/attachment/forum/202201/02/231748gbsjor2b233fouio.png "OPIDCC]JV]EQP1`9_SDJT%O.png")
选择刚刚配置的串口作为调试用。 ![8Z%KCQ6GWZQA]VLR[QTWHIL.png](data/attachment/forum/202201/02/231747d9mshxhxlyst6hxs.png "8Z%KCQ6GWZQA]VLR[QTWHIL.png")
点击add network,选择上述下载好的model点h5模型,选择压缩倍数8; 
点击分析,可从中看到模型压缩前后的参数对比 ![P}Q~0UPISV%Y36QQ]7R3(PX.png](data/attachment/forum/202201/02/231747hwlyewleh0y3meee.png "P}Q~0UPISV%Y36QQ]7R3(PX.png")
点击validation on desktop 在PC上进行模型验证,包括原模型与转换后模型的对比,下方也会现在验证的结果。 ![P(]J6HLQ4MKOI922Q~3X(IO.png](data/attachment/forum/202201/02/231746umn139318lr8vl43.png "P(]J6HLQ4MKOI922Q~3X(IO.png")
致此,模型验证完成,下面开始模型部署 04 模型转换与部署 时钟配置,系统会自动进行时钟配置。按照你单片机的实际选型配置时钟就可以了。EOZ2{)CR{VN%J.png")
B7BPIB`SZEHUC`6O.png")

最后点击GENERATE CODE生成工程。 ![EZOU]221[5%)R[G7SUUH))Y.png](data/attachment/forum/202201/02/231745peyyh9eyage7tyyh.png "EZOU]221[5%)R[G7SUUH))Y.png")
然后在MDK中编译链接。 
选择好下载器后就可以下载代码了。 F55}W8E@~IW4LX{`5.png")

然后打开串口调试助手就可以看到一系列的打印信息了。 ![T9OVQU]NLJ7)7S`W}37KLP6.png](data/attachment/forum/202201/02/231743wifd0zi5cxawdaia.png "T9OVQU]NLJ7)7S`W}37KLP6.png")
代码烧写在芯片里后,回到CubeMX中下图所示位置,我们点击Validate on target,在板上运行验证程序,效果如下图,可以工作,证明模型成功部署在MCU中。 G0H)`65L1@UO)E`{}$F.png")
![4)(Q2`~A]]I%4(~@A[~1%XM.png](data/attachment/forum/202201/02/231742as9x6ox9cso3z6so.png "4)(Q2`~A]]I%4(~@A[~1%XM.png")
这次就这样先跑一下官方的例程,以后再研究一下,跑跑自己的模型。 |
【福利三:逢7发帖赢大礼】4、基于STM32G070板子SPI flash 移植SFUD库
【福利三:逢7发帖赢大礼】基于STM32G070板子的uart shell移植设计
【福利三:逢7发帖赢大礼】3、基于STM32G070板子的YModem串口协议通信
【福利三:逢7发帖赢大礼】2、基于STM32G070板子的OLED移植U8G2库
实战经验 | ClassB功能安全认证代码与应用代码分区的实现要点
STM32G0 系列 I2C 通信异常典型案例分析与解决方案总结
经验分享 | LAT1490 两个STM32G0 I2C 通信异常的案例分析
经验分享 | STM32G0 I2C bootloader Go 命令后调试连接失败:DBG_SWEN 位复位修复
经验分享 | STM32G0B1 待机模式意外唤醒深度解析:RTC 结构体未初始化的隐形坑
经验分享 | STM32G0B1 待机模式意外唤醒深度解析:RTC 结构体未初始化的隐形坑
 微信公众号
微信公众号
 手机版
手机版