.png) STMCU小助手
发布时间:2022-1-18 20:08
STMCU小助手
发布时间:2022-1-18 20:08
|
【@.1 从位带操作开始】 初接触STM32的人一定花了不少时间用于理解其位带操作(bit banding)的原理与步骤。位带操作允许编程人员以字的单位读/写单一bit位。回想我们平时对于一个bit位的操作比如:↓ @-> PIN0 |= (1<<3); @-> PIN0 &= ~(1<<5); 虽然这只是一行代码,但是实际上这一行做了好几步的工作。比如第一行,首先读出当前PIN0的值放到缓存区,将1左移三位放入缓存区,将二者进行“或”操作,即将当前PIN0的第三位置位1,将结果存入到实际PIN0所在的地址,即更新了PIN0的值。当然实际写成汇编后可能步骤不见得一定一样,但是这几步工作是一定得做的。 而对于位带操作,STM32中将上述PIN0(假设它处于允许重新映射的区域,即位带区->Bit Band Region)的每一个bit位重新映射到了一个单独的地址,只需对这一个新的地址进行写操作,则原PIN0值的对应位自动置位或清零。假设刚才我们PIN0的第3bit位重新映射的地址我们用变量PIN0BIT3表示,则刚才的操作可以写作如下↓ @-> PIN0BIT3 = 1; //等同于PIN0 |= (1<<3), 这是由地址重映射保证的。 这一行的操作是,将1写入到PIN0BIT3所在的地址,即更新了PIN0BIT3的值,结束。由于地址重映射,将保证PIN0的第三bit位被置一了。可以看出,操作步骤比之前简单,因此同样的操作处理的速度更快了。 好,以上就是位带操作的原理,全部介绍完了,是不是很简单。接下来我们自然就想问了,这个PIN0第三bit位重新映射的地址在哪?这样地址重映射不是把内存扩大了么,允许重映射的地址会不会有限制?原地址跟重映射的地址之间有没有个换算公式将他们对应上? 
 在编程参考P25页可以找到,允许bit位重新映射的位带区只有两处,一处是SRAM区,一处是片内的外设区Peripheral,均有1M大小。熟悉的人一眼就看出来了,SRAM区里存放的是堆栈(heap, stack)、全局变量等,外设区Peripheral区就是我们操作这块CPU经常打交道的GPIO, TIMER, PWM, A/D等各个功能的寄存器的所在地址。重新映射的区域叫位带别名区(Bit band alias),均有32MB大小。也就是说,我们最终操作的地址都仅仅是1MB,那扩充出来的32MB空间无外乎是为了操作方便快速而设定的,最终还是得影响到那1MB空间才能起作用。编程参考的P30页以SRAM区介绍了这一对应关系↓ 
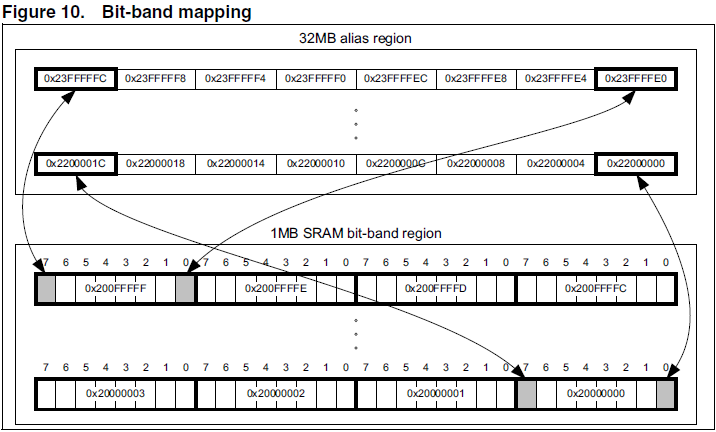 以0x20000000(1MB的开头)这SRAM最低地址为例,其第一bit位重新映射到了0x22000000(32MB的开头)地址上,第7bit位映射到了0x2200001C地址上,以此类推,到SRAM最高地址0x200FFFF(1MB的结尾)F的第7bit位映射到了0x23FFFFFC(32MB的结尾)。注意到上面跟下面的区域之间每个方格的地址增长区别,下面(bit-band region)每块方格地址增长1,而上面(alias region)地址增长4,因此有了编程参考的第P30页的关系转换计算公式↓ 
 好了,对于基础扎实熟悉的人来说到这里已经可以了,但是对于我,或者现在隐隐觉得有点疑问的人来说,可能对于这个换算的结果(1MB对应32MB)有点想进一步搞清楚这是为什么。为什么一会是字偏移(word_offset),一会是字节偏移(byte_offset),等等,字,bit,字节,是怎么对应的?等等,不是说寄存器都是32位的,怎么上面的对应图都是8bit(一字节)一对应的?晕了。所以这里有必要巩固一下这方面的基础知识。 【@.2 字,字节,半字与寻址方式】 首先回顾最基本概念。 在二进制中,从单纯数学上讲我们知道有 @-> 2^10=1024=1K @-> 2^20=1024*1024=1M @-> 2^30=1024*1024*1024=1G 最小二进制单位为比特(bit),即单纯的0,1,0,1,等等。对于音乐、图像等模拟信号我们进行压缩时通常采用的单位为比特率(bps),比如MP3最大比特率320Kbps,即每秒有320K个bit位,也就是每秒采样后的数字0,1的个数有320K个。一般CD的采样率为1411.2Kbps,因此音质就好很多了。普通VCD为1.25Mbps,DVD视频为5Mbps,标准蓝光为40Mbps,所以采用蓝光光盘的PS3游戏机的内部通信带宽比普通PC大很多也就是这个道理,因为每秒需要吞吐很大的数据量才能保证画面的清晰。 一个字节(Byte)等于8个bit,按照惯例我手写的B大写了。字节是通常的计算机存储的基本单位。我们通常所说的500GB硬盘、2GB内存就是指500个G的字节(Byte)和2个G的字节(Byte)。通常我们所说的32位处理器(比如ARM)的内存寻址范围为4GB就很好理解了。从单纯数学上讲↓ @-> 2^32= 4 * 2^30=4*1G=4G 最后,4GB的后面加了个B,即字节(Byte),表示是4G个字节数,因此32位处理器寻址范围为4G个字节。 若觉得4GB内存对于一些运算觉得不够用,采用64位处理器就可以这一问题,我们看看64位的寻址范围↓ @-> 2^64=2^34 * 2^30=16G*G 看到了吧,寻址范围能有16G*G个字节,远远大于32位处理器,连跳好几个数量级,足够满足很多应用了。一般G*G就称为E了,即64位处理器寻址范围为16EB。不过这么大的数我是已经没什么概念了。 最早的红白机,任天堂的FC,是一台8位机(MOS 6502),小时候玩的红白机觉得画面简单音乐粗糙,与其CPU性能不无关系。FC的接班人超任SFC采用了摩托罗拉的65836,3.58MHz的16位CPU,游戏画面和音质明显上了一个档次。掌机GameBoy(GB)和GameBoyColor(GBC)同为8位机。之后的GBA和NDS均采用了ARM系列芯片则直接是32位机了。这个网址可以很方便地查看GBA和NDS的硬件参数。32位主机时代PlayStation是王者可以说毫无疑问,而PS2你猜猜有多少位?64?不,人家直接跳到128位了。天文数字不是么,虽然PS2的CPU(Emotion Engion 简称EE)主频只有295Mhz。所以说现在很多PC端的PS2模拟器并不能很好的模拟就是这个道理。而到了PS3时代又回到了64位。不过要理解,单纯追求CPU的带宽并不一定能带来画面和性能的提升,其中架构的合理,缓存、外设时钟等等都会影响性能。 之后,为什么所有这些数字,4GB,16EB后面都要加个B(字节),为什么存储的单位是字节?这个问题我们先放一放,先来看看字(Word)的概念。 如果说比特(bit),字节(Byte)的概念比较好理解,那么字(Word)的概念就容易把人搞晕了,因为,字的长度并不统一,在不同CPU,不同时代,字的长度并不一致。从前的8位机上,比如前面提到的红白机的MOS 6502,字长为8bit,即一个字节。在一些16位CPU上,比如著名的8086,字长是16位的,2个字节。而现在的32位CPU比如ARM和我们手中的PC,字长是32位,即4个字节。 如果说,字节(Byte)对应于存储的单位大小,那么字(Word)则对应了CPU一次处理数据/指令的大小,因此才为了方便起了个字(Word)这个名字。对于ARM来说,字长是32位的,也就是4个字节。回想起ARM里所有的寄存器,是不是每个寄存器都是32位的?所以,以这个32位为单位进行操作,因此这个32位即为一个字(Word)。那么为什么之前说字节(Byte)是存储的基本单位呢? 对于ARM里面,数据的地址值跟数据自己本身都是32位的,这样做的好处是操作起来方便,统一。当然,对于ARMv4架构里的指令来说,有着32位的ARM指令集和16位的Thumb指令集,甚至对于Cortex M3来说都是32位或16位的Thumb指令集。这里先不讨论这种指令集之前的区别,仅仅以允许的最大指令为32位来讨论。另外,对于Cortex这一重回哈弗架构的CPU来说,指令和数据是分开的,完全可以不用同样的带宽访问(当然实际上STM32二者带宽还是一样的,方便操作,只是分开了而已)。 现代主流CPU的存储单元为字节(Byte),即物理地址的编码是以字节为单位编码的,一个地址对应于一个字节(Byte)或8个bit的空间,这一地址加上1,则对应于下一个字节或下一组8bit。这种物理地址的编码方式是由CPU的架构所保证的,并且为现在主流CPU所采用,因此说32位CPU的寻址范围是4GB就是指可找到物理地址上总共4G范围的区域,每一个区域上都有1个字节(Byte)的空间用于存放数据或指令。 那么很明显,对于ARM的寄存器来说,一块这样的1个字节区域肯定是不够的,每个32位的寄存器需要4个这样的区域来存放才可以。我们经常可以看到在定义寄存器时使用了下面的语句↓
以上寄存器在内存里是相互连续的,我们可以很清楚的看到,他们之间的地址值的增量为4。这就很清楚了,相邻寄存器地址值差4,实际上之间有4*1Byte的空间,即4*8bit=32bit的空间,这一空间刚好可以容下一个32bit的寄存器值存放。实际上,你可以看到几乎所有访问寄存器时的地址值的末尾均为0,4,8,C,即寄存器们一个挨着一个,32bit为一组,塞满了他们所在的一片物理地址区域。因此对于32位CPU来说,出于效率一般均按字访问,即访问地址末尾为0,4,8,C的物理地址,一次访问到4个字节,不会单独访问其他地址,比如地址末尾为1的物理地址。当然,还有所谓的以半字(Half-Word)方式访问,例如Thumb指令集,一次访问2个字节,访问地址末尾为2的倍数的物理地址。 好了,那怎么保证访问到这个地址时能读取到32bit的数据,且他们并不错位、顺序相反呢?这就涉及到字节的对齐问题。 【@.3 字节对齐,字节序 Endianness】 我们先分析一下前面的一条预定义 @-> #define IOPIN0 (*((volatile unsigned long *) 0xE0028000)) 这是一个指针的写法。首先当访问一个已知地址值的内容时我们可以先定义一个指针,比如↓ @-> (uint32*)0xE0028000 //当然也可以是unsigned int来代替uint32,都可以。 即将地址位于0xE0028000的数据用指针来表达。对于这一指针,uint32是一个32位的数据结构,限制了这一指针指向的内容是以0xE0028000开始往地址增长方向,共计4个Byte,32bit的这么一块区域,其数据结构是uint32。之后我们需要得到这个指针的值,那么很简单,用*运算取值即可↓ @-> ( *( (uint32*)0xE0028000 ) ) //我故意多留了空格,目的是为了看得清楚。 这样一整块就得到了0xE0028000这一地址上的值,剩下想要读取或写入都可以了。原本的宏定义中用到的数据类型是unsigned long,也是32位无符号型整数,加上volatile修饰,表示编译器对这个数不做优化处理。大小确定了之后,现在我们看着这4个字节,假如其中的内容如下(还记得每个地址上存放的是一个字节么),以十六进制表示↓ @-> 0xE0028000 :0xDD @-> 0xE0028001 :0xCC @-> 0xE0028002 :0xBB @-> 0xE0028003 :0xAA 当读取时,你认为我们最终得到的值是什么样的?是0xDDCCBBAA(高位数存在地址低位),还是反过来的0xAABBCCDD(高位数存在地址高位)?想一想。 关于这一点,就是CPU在设计时最有争议的地方,许多芯片厂商在设计时也并没有很好的统一。习惯上将,规定第一种存储方式,即高位数存放在地址低位,称为大端(Big-endian),而第二种存储方式,即高位数存放在地址高位,称为小端(Small-endian)。对于我们来说,觉得小端对齐方式更符合常规思维,高位对应高地址,地位对应低地址。可以从这个wiki网址参考有哪些硬件使用大端,哪些使用小端。注意ARM架构是可以Bi-endian的,即可设置为大小端的一种,只不过我们常用的ARM芯片被制造商设置为小端,大小端设置的寄存器位往往设为只读,只能通过REV指令零时调换存储大小端而已。 回过头看看我们访问寄存器时,已知了地址值0xE0028000,并且我们需要读取4Byte,即32bit因此需要设立变量为unsinged long,我们也知道了读取后的字节顺序为小端,因此对(*((volatile unsigned long *) 0xE0028000)) 这样一句话的操作就恰好对应为我们需要的4个Byte的顺序正确的寄存器值,我们在对嵌入式的寄存器进行操作时也都是这么做的而且运行的很好。 【@.4 再看位带操作】 
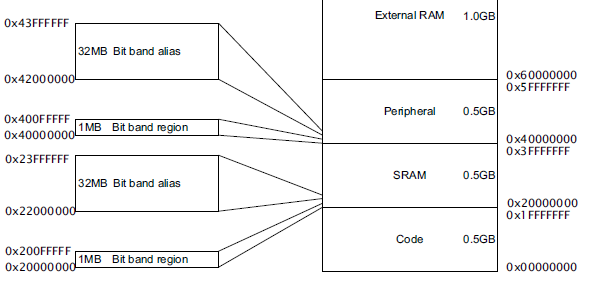  之前提到的两个区域,SRAM区和Peripheral区都有位带操作区,这样一来↓ IN A NUTSHELL: @-> 位带区(Bit band region)中的每一个bit均扩充到别名区(Bit band alias)上的一个字(Word),即4个字节(Byte),32个bit,因此总共1MB的位带区被扩充为32MB的别名区。 @-> 为什么每一个bit位要扩充为一个字(Word)而不是字节(Byte)?因为CPU进行常规操作都是以字(Word)为单位访问地址的。所以位带区的相邻一bit映射到别名区的地址增量是4,正好是4个字节(Byte),一个字(Word)。 之前提到的,编程手册中给出的别名区和位带区之间的计算公式,我想只要你有高中知识,用数学归纳法就可以推导出来了。选择几个实际地址试试看,你就明白了。↓  
在实际操作中,根据Cortex-M3权威指南,可以根据如下宏定义进行位带操作。以GPIOA口的控制输出引脚寄存器ODR为例,有如下定义
|
【福利三:逢7发帖赢大礼】4、基于STM32G070板子SPI flash 移植SFUD库
【福利三:逢7发帖赢大礼】基于STM32G070板子的uart shell移植设计
【福利三:逢7发帖赢大礼】3、基于STM32G070板子的YModem串口协议通信
【福利三:逢7发帖赢大礼】2、基于STM32G070板子的OLED移植U8G2库
实战经验 | ClassB功能安全认证代码与应用代码分区的实现要点
STM32G0 系列 I2C 通信异常典型案例分析与解决方案总结
经验分享 | LAT1490 两个STM32G0 I2C 通信异常的案例分析
经验分享 | STM32G0 I2C bootloader Go 命令后调试连接失败:DBG_SWEN 位复位修复
经验分享 | STM32G0B1 待机模式意外唤醒深度解析:RTC 结构体未初始化的隐形坑
经验分享 | STM32G0B1 待机模式意外唤醒深度解析:RTC 结构体未初始化的隐形坑
 微信公众号
微信公众号
 手机版
手机版










