.png) STMCU小助手
发布时间:2022-7-6 15:05
STMCU小助手
发布时间:2022-7-6 15:05
|
DSP简介 STM32F4 采用 Cortex-M4 内核,相比 Cortex-M3 系列除了内置硬件 FPU 单元,在数字信 号处理方面还增加了 DSP 指令集,支持诸如单周期乘加指令(MAC),优化的单指令多数据指 令(SIMD),饱和算数等多种数字信号处理指令集。相比 Cortex-M3,Cortex-M4 在数字信号处 理能力方面得到了大大的提升。Cortex-M4 执行所有的 DSP 指令集都可以在单周期内完成,而 Cortex-M3 需要多个指令和多个周期才能完成同样的功能 以上都不重要。重要的是,它运算快就完了!!!具体多快,我们后面会有相应测试 一、可供移植的DSP文件 STM32F4 的 DSP 库源码和测试实例在 ST 提供的标准库,详细路径为:光盘→8,STM32 参考资料→STM32F4xx 固件库→STM32F4xx_DSP_StdPeriph_Lib_V1.4.0→Libraries→CMSIS→ DSP_Lib。 DSP_Lib 源码包的 Source 文件夹是所有 DSP 库的源码,Examples 文件夹是相对应的一些 测试实例。这些测试实例都是带 main 函数的,也就是拿到工程中可以直接使用。接下来我们一 一讲解一下 Source 源码文件夹下面的子文件夹包含的 DSP 库的功能。 BasicMathFunctions 基本数学函数:提供浮点数的各种基本运算函数,如向量加减乘除等运算。 CommonTables arm_common_tables.c 文件提供位翻转或相关参数表。 ComplexMathFunctions 复杂数学功能,如向量处理,求模运算的。 ControllerFunctions 控制功能函数。包括正弦余弦,PID 电机控制,矢量 Clarke 变换,矢量 Clarke 逆变换等。 FastMathFunctions 快速数学功能函数。提供了一种快速的近似正弦,余弦和平方根等相比 CMSIS 计算库要快 的数学函数。 FilteringFunctions 滤波函数功能,主要为 FIR 和 LMS(最小均方根)等滤波函数。 MatrixFunctions 矩阵处理函数。包括矩阵加法、矩阵初始化、矩阵反、矩阵乘法、矩阵规模、矩阵减法、 矩阵转置等函数。 StatisticsFunctions 统计功能函数。如求平均值、最大值、最小值、计算均方根 RMS、计算方差/标准差等。 SupportFunctions 支持功能函数,如数据拷贝,Q 格式和浮点格式相互转换,Q 任意格式相互转换。 TransformFunctions 变换功能。包括复数 FFT(CFFT)/复数 FFT 逆运算(CIFFT)、实数 FFT(RFFT)/实数 FFT 逆运算(RIFFT)、和 DCT(离散余弦变换)和配套的初始化函数 !!! 所有这些 DSP 库代码合在一起是比较多的,因此,ST 为我们提了.lib 格式的文件 .lib 格式文件路径:光盘→8,STM32 参考资料→STM32F4xx固件库→STM32F4xx_DSP_StdPeriph_Lib_V1.4.0→Libraries→CMSIS→Lib→ARM。根据自己的需求选择不同的.lib文件。 我们所用的STM32F4 属于 CortexM4F 内核,小端模式,应选择:arm_cortexM4lf_math.lib(浮点 Cortex-M4 小端模式)。 示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。 二、arm_cortexM4lf_math.lib 1.可使用的DSP函数 我们打开.lib文件可看到,里面存有编译后的.o文件,也就是提供可使用的DSP函数。 根据函数名可以粗略了解其含义,也可以度娘搜索DSP函数XXX,即可查到其含义。 后续将在实验中一一讲解。 代码如下(示例):
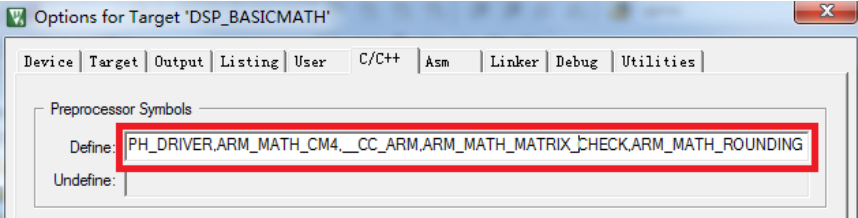
2.工程移植 1、添加文件。 首先,我们在例程工程目录下新建:DSP_LIB 文件夹,存放我们将要添加的文件:arm_cortexM4lf_math.lib 和相关头文件,然后,打开工程,新建 DSP_LIB 分组,并将 arm_cortexM4lf_math.lib 添加到工程里面。 2、 添加头文件包含路径 添加好.lib 文件后,我们要添加头文件包含路径,将第一步拷贝的 Include 文件夹和 DSP_LIB 文件夹,加入头文件包含路径。 3、 添加全局宏定义 最后,为了使用 DSP 库的所有功能,我们还需要添加几个全局宏定义: 1,__FPU_USED 2,__FPU_PRESENT 3,ARM_MATH_CM4 4,__CC_ARM 5,ARM_MATH_MATRIX_CHECK 6,ARM_MATH_ROUNDING 
这里,两个宏之间用“,”隔开。并且,上面的全局宏里面,我们没有添加__FPU_USED, 因为这个宏定义在 Target 选项卡设置 Code Generation 的时候(上一章有介绍),选择了:Use FPU (如果没有设置 Use FPU,则必须设置!!),故 MDK 会自动添加这个全局宏,因此不需要我们 手动添加了。同时__FPU_PRESENT 全局宏我们 FPU 实验已经讲解,这个宏定义在 stm32f4xx.h 头文件里面已经定义。 这样,在 Define 处 要 输 入 的 所 有 宏 为 : STM32F40_41xxx,USE_STDPERIPH_DRIVER,ARM_MATH_CM4,__CC_ARM,ARM_MATH_M ATRIX_CHECK,ARM_MATH_ROUNDING 共 6 个。 至此,STM32F4 的 DSP 库运行环境就搭建完成了。特别注意,为了方便调试,本章例程我们将 MDK 的优化设置为-O0 优化,以得到最好的调试效果。 |
【福利三:雨露均沾·逢7狂欢】之四:用一个定时器同步另外两个定时器输出PWM
【逢7发帖赢大礼】STM32开发之WIFI实时时钟
【逢7发帖赢大礼】STM32开发之指纹识别!
【逢7发帖赢大礼】STM32开发之环境空气质量监测
【逢7发帖赢大礼】STM32开发之人体实时运动信息监测!
【逢7发帖赢大礼】STM32开发之IC门禁卡UID读取方法!
【逢7发帖赢大礼】全网最简单的Arduino_STM32开发环境搭建教程!
STM32F4中文用户手册
STM32F400、STM32F402 Cortex-M4超值单片机
SPI 高温读错最后一位?STM32F42xx 官方根治方案
 微信公众号
微信公众号
 手机版
手机版