.png) STMCU小助手
发布时间:2021-12-10 10:17
STMCU小助手
发布时间:2021-12-10 10:17
|
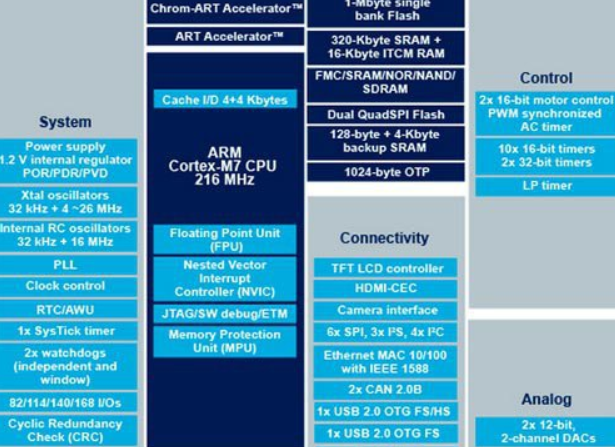
一、STM32F7 资源 当第一眼看到STM32F7的数据手册Datasheet和参考手册Reference manual时!可以说是抑制不住的兴奋!尽管ST所研发的这款基于Cortex-M7的芯片与当初ARM公司发表声明Cortex-M7内核时所声明的无论是在功耗、频率等还是有一定差异的!但是这或许只能理解为ST为了快速的推出第一款基于Cortex-M7内核的MCU而没有做好充分的准备,在后续的研发中更加的以提高各方面的性能而达到当初ARM公司所预期的效果(具体的情况有很多,比如:ARM声明Cortex-M7内核大支持800MHz的主频,并采用28nm工艺,但是从资料得知STM32F7采用了90nm工艺,高主频为216MHz。当然,Atmel的SAM V71也只是高支持300MHz,并且在价格上比STM32F7高的太多了,基本上就是土豪玩的。还获得Cortex-M7内核使用授权的是飞思卡尔半导体,但是目前到现在还没有声音,也不知道情况;但是基本上可以看出来,各个半导体厂商想要把Cortex-M7内核的性能、功耗等提高到接近评估极限,可能还是需要一段时间的!我们拭目以待)。 当进入ST官网,找到STM32F7 Discovery板卡板载的芯片STM32F746NGH6芯片的主页时,第一眼就看到了如下的关于这款芯片的资源框架图:
就这个图,如果拿去对比同样是ST的Cortex-M3内核的资源图和Cortex-M4内核的资源图,就会发现,基本上各类资源在不停的往上增加,而且是呈几个等级的往上拉!当然,也有一点是,M7和部分M4无论是在资源上还是在主频上,都很接近或者说相似!那么M7到底提高在哪里了呢?那么就慢慢的体味了。 STM32F746NGH6资源: ·ARM 32bit Cortex-M7内核+FPU+Chrome-ART加速器、CPU高主频216MHz、1MB闪存Flash、320KB SRAM ·3个12位精度ADC控制器,共有24通道AD ·2个12位DA控制器 ·18个定时器,2个先进控制定时器+1个低功耗定时器+12个通用定时器+2个看门狗定时器+SysTick滴答定时器 ·3个DMA控制器 ·支持SWD、JTAG工具调试,支持Cortex-M7单元跟踪 ·多支持168个I/O口,其中164个I/O口的翻转速率高达108MHz,166个I/O口兼容5V器件端口 ·4路I2C接口(SMB/PMB)、4路USART、4路UART、6路SPI、3路I2S ·2路SAI、2路CAN2.0、SDMMC、SPDIFRX、HDMI-CEC、USB OTG HS、USB OTG FS、以太网口、Camera摄像头接口、LCD-TFT接口 资源好多哇!但是,其实这也没什么,如果仅仅是单纯的增加硬件外设资源,那就没什么谈的了,因为人家8051内核的单片机在一定条件下也照样能集成各种硬件资源接口,那么Cortex-M7到底增强在哪里呢? (1)高性能和可配置性:在ARM Cortex-M系列处理器中,想都不用想,在目前为止Cortex-M7内核是强悍的,性能是为出色的(否则ARM就没有必要力推它了)。它拥有六级超标量流水线(注意哦,是六级超标量哦,这就意味着指令的执行就像飞一般的感觉(意味着一个时钟周期能处理更多的指令),去查看看M3和M4内核是多少级流水线,看看是不是一个等级的)、系统接口和内存接口灵活配置(包括AXI和AHB)、缓存cache(STM32F7共4KB data cache和4KB instruction cache(即4KB数据缓存和4KB指令缓存),知道这意味着什么吗?)、高度紧密耦合内存TCM(Tightly-Coupled Memory (TCM) interfaces;STM32F7:64KB Data TCM RAM,16KB instruction TCM RAM)、为MCU提供更加出色的整数和浮点的DSP。 (2)系统兼容性:Cortex-M7是基于已经在市场上大获成功的Cortex-M3和Cortex-M4处理器的基础上构建的新内核,所以无论在电源系统还是Debug调试系统上基本与其他Cortex-M系列相兼容;并且增加了通过内存ECC提供的错误功能,全面跟踪(Trace)以及全面安全,能很好的协助厂商应对与各种市场(或者敏感市场)。 关于以上列出的个点,有必要解释一下几点: (1)、Cortex-M7使用了6级超标量流水线,意味着MCU在一个时钟周期内能处理更多的指令,但是有一点,流水线增加的实现代价是以空间换时间。 (2)、Cortex-M7采用了紧密耦合内存技术TCM(Tightly-Coupled Memory (TCM) interfaces),TCM这个名词可能有人很陌生(玩过比较少东西的入门者,我在这里废几句口舌)。ARM的RAM包括:静态RAM、动态RAM和TCM紧密耦合内存Tightly-Coupled Memory)。 TCM是一个固定大小的RAM,紧密的与处理器内核相耦合,提供与cache相当(一个级别)的性能,并且与cache相比它的优点是:程序代码可以精确被控制(例如,精确的将某段代码或者某个函数放在RAM指定的地址位置),cache还有命中和命不中的可能。当然TCM永远不会被踢出主存储器。因此它有一个被用户预设的性能,而不是像cache那样是统计特性的性能提高。 (3)Cache缓存:上面说了那么多的cache缓存,而且在STM32F7上也使用了cache缓存(4KB data cache和4KB instruction cache(即4KB数据缓存和4KB指令缓存)),那么cache缓存到底是什么呢??其实,cache缓存是用静态RAM组成的一段缓存空间,它的速度与CPU差不多,所以使用它来做CPU和内存之间的缓存;但是高速率也就确定了它的造价非常高。 (4)DSP,Cortex-M7的DSP和Cortex-M4的DSP已经不是一个级别的了,Cortex-M4的DSP也就是高能做单精度浮点运算,到双精度级别的,基本上只能由软件来玩了,但是,软件处理浮点运算,想想都知道CPU被耗(耗时)成啥样了,而且还是MCU,这样会造成MCU的效率特低;但是在Cortex-M7上就不存在这样的问题了,需要处理双精度的浮点运算,直接使用硬件DSP运算即可。一个字,“爽”。 其实还有好几点关于外设的改善,也一并列出来: (5)SDRAM:从STM32F7系列MCU的参考手册《STM32F75xxx and STM32F74xxx advanced ARM®-based 32-bit MCUs-Reference manual》可以看到它支持一种叫FMC的接口,这个接口好像没见过,但是玩过Cortex-M3和Cortex-M4的童鞋肯定都见过FSMC(Flexible static memory controller,灵活的静态存储控制器,当需要控制外部总线时,就用这个接口(比如NOR Flash、Nand Flash等)),咋一看,FMC和FSMC就一个字母只差(因为都是缩写,从专业英语的角度来看,这个一般情况下在同一行业中,代表的单词是一样的),那么从手册中得到:FMC英文为Flexible memory controller,果真是只差一个单词哦,那么就翻译为,灵活的存储控制器吧。那么一个单词只差,它们到底有什么区别呢?其实,两者相比较,FCM就是只差了SDRAM,这一点非常重要,这意味着无论是对于程序员还是对于用户,有更多内存就可以提高系统的性能;在参考手册中提到,对于FCM就似的使用SDRAM就像使用SRAM一样方便;并且SDRAM控制器支持两个独立的SDRAM Bank,可以在8/16/32位总线宽度之间独立选择,控制器包括13位行地址和11位列地址,4个内部Bank,那么计算一下就可以知道:它高可以支持256MB的外部SDRAM!啊啊啊啊啊!256MB啊啊啊啊!这在MCU界绝对是王者霸者了!(除非等到以后有更牛X的来冲击)。 (6)QSPI:全称是Quad SPI,这是一种特殊的通讯接口,从官方资料看到:QSPI协议接口可以有三种工作模式:间接模式、查询模式和内存映射模式。啥??内存映射????映射什么?怎么映射?映射后的结果是啥?(。。。。。一堆问题接踵而至,根本停不下来),那到底是什么个情况呢?(咱得好好的想想,组织组织语言)。。。。。。。,嗯!就比如在房间中点蜡烛,不开灯的情况下,烛光(片内Flash)还是很亮的,只是范围小点,人在室内的活动范围空间就会受到光线的限制,而当开电灯后,灯光一下子就把整个房间给照亮了,这也意味着,人的活动范围变大了,有可能活动范围的限制因素不再是光线了,可能是其他的比如墙(外部存储空间大小)之类的了。这就构成了一个映射的关系,而且映射了之后,人的范围扩大是必然的,不需要付出任何代价的。咦!貌似上面就有个非常好的例子哦,上面所说的FCM接口对SDRAM的情况就是一种映射啊!嗯!就是这样!所以设想一下,当我们把SPI Flash进行初始化后,将他映射到MCU的4G的线性空间上,然后将代码copy到这段空间内,然后咱就让CPU在上面运行程序,呵呵!这不就想是在使用自己的东西了吗?(如果玩过在ARM9、ARM11、Cortex-A7、Cortex-A8等平台上跑Linux等嵌入式操作系统,那这种方法见怪不怪了!但是、但是这是MCU哇!还是很惊讶很期待的哦!)。 (7)DMA2D,这是啥呢?好像是DMA哦,但是这“2D”是啥啊?无论是在STM32F7的Datasheet上还是在参考手册上,我们都能看到有DMA1、DMA2、DMA2D,很明显,三个都是DMA,前两个就是普通的DMA,后的一个多出来了一个缩写字母D就应该值得被关注了。那么它到底是什么?在参考手册中居然用一章的内容来讲解DMA2D,而前两个也就是一章内容,那么可想而知它和DMA1、DMA2是有区别的。DMA2D,英文是:Chrom-Art Accelerator™ controller,即Chrom-Art加速器控制器,那么Chrom-Art加速器是什么东东呢?通过查看资料才得知,Chrom-Art加速器就是一种专门致力于图像数据操作的DMA,OK!很明显了!这个DMA2D就是专门用来搬运图像显示数据的,这样当用到LCD显示器是,可有福了,有专门的DMA搬数据,就不需要CPU用缓存慢慢的刷图片了!想想就是爽啊。 其他的也还有好多新接口!但是也就是相应支持啦!所以就没不要细究了! 说明:以上一些内容我是参考了Cortex-M7架构手册《ARM® Cortex®-M7 ProcessorRevision r1p1-Technical Reference Manual》,此手册文档在ARM官网获取:http://infocenter.arm.com/help/index.jsp 此手册为ARM公司所发布,详细讲述了Cortex-M7内核的各种资源和关于Cortex-M7内核架构的技术参考,可作为底层开发和了解Cortex-M7内核的重要技术文档。他有多个更新版本(目前有三个),选择适合的参考即可。 二、STM32F7架构 在这里我用架构这个词就有点感觉像是吹牛X的样子,其实我只是分析一下从STM32F7系列MCU参考手册上理解到的信息,并做记录。毕竟对于Cortex-M7内核的MCU,还太新了(到至今为止距离ARM发布Cortex-M7内核才过大半年时间)!资料极少,只能硬着头皮啃了! 不管怎么样,只要是做开发,一切都要从参考手册《STM32F75xxx and STM32F74xxx advanced ARM®-based 32-bit MCUs-Reference manual.pdf》为基准。 打开STM32F7熄灭MCU参考手册,只要是阅读过ST的技术文档,都会知道,第一章必定是“文档约定”,主要是约定一些资源的关键词和外设的关键词等。这一点!也是非常重要的,如不了解,可能有些东西你压根不知道这代表的是什么。但是这了解就好! 重点来了!在内容的开篇,ST毫不客气的就来了一张图,并且这个图概括了STM32F7的整一个系统架构。如下图:
那么这个图到底是什么图呢?它的作用是什么呢?手册上标题首先就给出了,System architecture(系统架构) ,果真是ST的系统架构图,那么这就意味着,想要对STM32F7进一步的进行了解,就必须从系统架构图了解,从而了解整一个STM32F7的系统架构。OK!迫不及待了!咱开始吧! 首先,在整个F7的架构中,存在2条系统总线(这一点非常重要),分别是: (1)一个A**线到多个AHB总线的桥,即AXI4协议转换为AHB-Lite协议。其中有: ------1个A**线到64Bit的AHB总线的桥用来连接到片内嵌入式Flash ------3个A**线到32Bit的AHB总线的桥用来连接到AHB总线矩阵 上面的几句话基本上是理解翻译手册,那么,AXI到底是啥玩意呢?那么吊的样子!(可能很多人对他比较陌生)!其实,AXI(Advanced eXtensible Interface)是一种总线协议,该协议是ARM公司提出的AMBA(Advanced Microcontroller Bus Architecture)3.0协议中的重要部分,是一种面向高性能、高宽带、低延迟的片内总线。它的地址/控制和数据是分离的,支持不对齐数据传输,同时在突发传输中,只需要首地址,同时分离的读写通道、并支持Outstanding传输访问和乱序访问,更加容易进行时序收敛。AXI计算丰富了现有的AMBA标准内容,主要用于满足超高性能和复杂的片上系统(SOC)设计需求。(此段话是我从度娘上抄的!呵呵!) 基本上了解了AXI是什么东西之后,基本上也就明白了这一条系统总线的作用了。 (2)一个multi-AHB总线矩阵。 到这里,如果是狐狸的话,尾巴就露出来一点点了!那么继续贴图:
这个图,其实就是上面的那一个系统架构图喽!只是我加了点料!嘿嘿! 那么从图中可以看出,整个multi-AHB总线矩阵贯穿所有的主/从总线,使得他们之间互联。对于64-bit multi-AHB总线矩阵从CPU通过A**线到AHB总线的桥和32-bit AHB总线的GP DMA和外设DMA扩大到64位片内Flash。 在图中也体现出了多AHB总线矩阵互联的现象(在ST其他系列MCU中,我们经常看到的总线矩阵只是一个框内写着总线矩阵,ST并没有画出总线矩阵图,构成了什么样的矩阵,但是在F7总,总线矩阵终于得到了体现,如上图所示),从图中可以看出,在总线矩阵内部包括了12个总线“主机/主总线”和8个总线“从机/从总线”。 (1)12个总线“主机/主总线”: ——3个32位AHB总线连接到Cortex-M7 AXI主总线与64位AHB的桥。 ——1个64位AHB连接到片内嵌入式Flash。 ——Cortex-M7 AHB外设总线。 ——DMA1内存总线 ——DMA2内存总线 ——嵌入式DMA总线(用于指令和数据的读/写,存取) ——USB OTG HS DMA 总线 ——LCD 控制器DMA总线 ——Chrom-Art加速器(DMA2D)存储总线 (2)8个总线“从机/从总线”: ——片内Flash AHB总线(Flash读/写访问,代码执行和数据访问) ——Cortex-M7 AHBS从总线DMA数据传输接口DTCM RAM(数据TCM) ——内部主SRAM1(240KB) ——内部副SRAM2(16KB) ——AHB1外设包括AHB到APB的桥和APB外设 ——AHB2外设包括AHB到APB的桥和APB外设 ——FMC(上面解释了) ——Quad SPI(上面也解释了) 基本上整一个总线矩阵就是以上内容了!好复杂的样子,12 X 8的矩阵哇!嗯!那么为了跟清楚了理解其,继续往下。 1、关于Multi AHB总线模型,其实它是作为管理系统主总线与各总线之间访问仲裁(相当于公司的董事长),它的实现是使用一个循环算法。它提高了从主总线到从总线的效率,支持并发访问和高效访问,即使几个高速外围设备同时工作。但是需要注意的是:DTCM和ITCM RAM不属于这种总线模型。数据TCM RAM的访问是GP-DMA和外设DMA通过特定的AHB从总线到CPU。 2、整个系统中存在两个AHB/APB桥,与APB1和APB1形成完整的同步联系,并且运行灵活的外围频率选择。 3、CPU的AXIM总线用来连接指令和数据总线到Cortex-M7 FPU内核的,通过multi-AHB与AXI之间的桥进行联系。一共有4种总线访问模式: ——CPU A**线访问1:这个A**线的目标是融合(或映射)外部FMC接口内存(包括代码和数据)。并且规定NAND的映射地址为0X80000000到0X8FFFFFFF,这个MPU属性可由软件进行配置。 ——CPU A**线访问2:这个A**线的目标是外部Quad SPI内存(包含代码和数据)。 ——CPU A**线访问3:这个A**线的目标是内部内存SARM1和SRAM2(包含代码和数据)。 ——CPU A**线访问4:这个A**线的目标是内部Flash的映射(包含代码和数据)。 嘿嘿!到这里,已经再清楚不过了!AXI到底是干啥用的,怎么用的都清楚了! 4、ITCM总线和DTCM都是高速缓存,既然是高速(那意味着造价很高),那么应该是作为特殊用途的(要是全部都用这种缓存技术,我觉得芯片的价格肯定会比黄金价格要高很多,数据量是无限大的),所以一般应该数作为比如对时间要求很严格的代码就可以放在ITCM中,为了提高运行速度,某些需要频繁存取的数据也可以放到DTCM中进行缓存,以节省时间。所以ITCM总线是Cortex-M7内核作为指令获取和数据访问Flash ITCM映射接口和指令获取ITCM RAM的。而DTCM是Cortex-M7作为数据访问的缓存,但是它也可以作为指令的获取。 5、CPU AHBS总线是Cortex-M7内核与AHB从总线连接的总线模型,它通过实验DMA和外设DMA进行数据传输到DTCM RAM。但是AHBS无法访问ITCM总线,所以不支持从DMA将数据传输到ITCM RAM。并且对于DMA传输到Flash ITCM接口,所以的传输都强行在AHB总线进行。 6、AHB外设总线是Cortex-M7内核与外设建立连接的总线模型,这使得内核可以对外设进行数据访问。 关于DMA,它访问各种外设,状态可能各有一些变化,如下: 7、DMA memory总线使得DMA主总线与内存建立联系的总线模型,它使用直接存储器存取执行转移到存储器。它的目标数据的存储:内部SRAM1,SRAM2和DTCM 内部Flash和外部映射FMC存储或Quad SPI存储。总之是专门访问内存的。 8、DMA外设总线就是主总线与外设之间建立联系的总线模型了,它使用直接存储器存取访问AHB外设或执行内存到内存的传输(这就是我们常用的DMA啦),它的目标是:AHB和APB外设以及内存SRAM1,SRAM2和DTCM 内部Flash和外部映射FMC存储或Quad SPI存储之间的数据运输。 9、以太网DMA总线是连接以太网主接口的总线模型,它向以太网接口加载数据或者运输以太网数据到内存。 10、USB OTG HS DMA总线是建立起与USB OTG HS主接口的总线模型。它同样是向USB加载数据或者从USB运输数据到内存。 11、LCD-TFT控制器DMA总线是建立起与LCD控制器的总线模型。他向LCD加载数据或者从LCD搬运数据到内存。 12、DMA2D是图像加速器总线模型,这个总线使用DMA2D图形加速器加载/存储数据到内存,它的目标数据存储:内部SRAM1,SRAM2和DTCM内部Flash和外部映射的FMC和Quad SPI存储器,还有闪存。 OK!整一个分析就是这样!计算F7的系统架构就是上面的第一个图,后面无非是做一些解释罢了!在这个新东西中,或者说在MCU界中,它还真出现了好多新名词哇(反正对于我来说是新的)。所以要理解起来!还真有一定难道!上面的有些逻辑或者表达比较生硬!不过这也是无奈之举,毕竟在下实力有限嘛!OK!就不多说了!关于这份文档,从阅读和写文章,基本上花了4天的时间(不包括我的工作时间),想想还是很辛苦的!嘿嘿!不过幸好现在触摸到一点点东西了!努力加油吧! 声明:上述文章纯粹个人理解(有几处是从度娘获取),如若有理解不足和错误,还望请联系我!让我也进一步学习!技术总是需要交流才有进步嘛! |
STM32F745 USART1 Bootloader启动失败排查与解决的流程分析
STM32芯片命名规则
STM32 引脚到底有多少?为什么一个引脚能当好几个用?
入门嵌入式,为什么STM32是“优选起步”?
嵌入式-单片机-STM32 EXTI中断
STM32单片机进行除零运算,为何程序不崩溃?
STM32 LL为什么比HAL高效?
STM32时钟详解
2025国庆中秋活动体验报告2——TouchGFX的UI设计
2025国庆中秋活动体验报告1——TouchGFX环境配置
 微信公众号
微信公众号
 手机版
手机版