.png) STMCU小助手
发布时间:2022-2-26 16:28
STMCU小助手
发布时间:2022-2-26 16:28
|
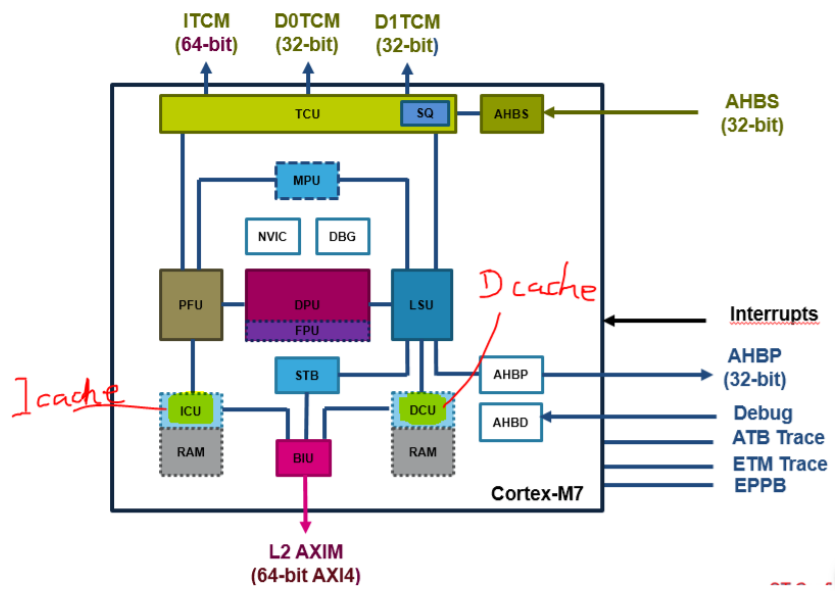
前言 本文会从结构,原理以及应用方面对 MPU 和 Cache 进行分析,主要目的是希望读者对 Cache 有基本的了解,在具体的实际应用中,使用带有一级 cache 的 MCU 时,避免常见的错误。- Q, D3 n L) ^- e Cache 介绍 Cache 及其原理/ j7 e9 m1 `# t( c" ^ Cache,高速缓存,一般指的是 L1 cache,即和 Core 紧耦合的,从 STM32F7 系列开始,基于 ARM cortex-M7 内核,增加了对 L1 Cache 的支持。 : A6 T/ r- L! L* } 
从这张图片可以看出来,无论是指令 Cache(I-cache)还是数据 Cache(D-cache),一旦使能之后,就分别与 Core 的 prefetch unit(I-cache)和 load-store unit(D-cache)相连,以 D-cache 为例,因为直接与 LSU 相连,访问速度会比直接访问 SRAM 或外部 RAM 快很多,只要保证 cache 有足够高的命中率(由 cache 策略保证),尽量少的 cache miss,读/写的速度会有比较大的提高。+ o+ `8 y, y0 K) [ 结构及策略7 b. Q; ?2 @: h6 o8 Y; q m+ ] 同样这里以 D-cache 为例,看一下 D-cache 的构成: 
包括 Address 和 cache-line,Address 表明其地址,对应一条包含 32bytes 的 cache-line:% x7 ~( l7 x: e+ P, x4 D* y 读数据时,当地址命中时即 cache-hit,便可以直接从 cache line 中取出相应的数据,反之,当遍历了address 都没有找到,就会产生 cache-miss,这时便会从实际的内存单元(如 SRAM)中取出相应的数据,并更新到某一条 cache-line 中并修改相应的 cache-line 信息;7 }+ h: r) v, A! R. G7 ^/ [ 写数据时,就有点不同了,包括 write-through 策略和 write-back 策略,当使用 write-though 策略时,更新 cache-line 的同时,同样会更新其对应的实际物理地址的区域,当采用 write-back 策略时,更新cache-line 的同时,并不是马上去更新其对应的实际物理地址的内容,而是在其认为合适或者所有的cache-line 都 dirty 的时候才会去更新,当然,也可以通过软件让其强制更新,即 clean 的动作,这一块会在后面的 cache 一致性问题上也会有体现; 同样,对于为什么将 cache 拆分为 2-way 或是 4-way,这和 cache 自身的策略如查找算法等相关,由于本文侧重讨论 cache 的应用相关问题,所以关于 cache 本身的策略这里不再详述。: O4 u' H0 w$ T1 Q+ \) s" j Cache 及 MPU 属性- u! |4 L6 ]: G# ]; C5 T* R 这里需要注意的是,cache 一般是配合 MPU(memory protection unit)一起使用的,首先需要通过 MPU配置相应 memory 的属性(normal, strongly-ordered, device, XN etc.),如下表所示: ![Z[@$LNTW{4W{]~YJGQ(IK)W.png](data/attachment/forum/202202/26/162935ymy7tj20o7vv0qmv.png "Z[@$LNTW{4W{]~YJGQ(IK)W.png")
选取几个有特点的作为示例: 0~0x1FFF_FFFF: flash 空间,属性为 normal,cache 的属性为 Write-through,即更新 cache 的同时,将数据同时写入相应的物理地址空间! g9 p2 S# ?# g) n- R2 s 0x2000_0000~0x3FFF_FFFF: SRAM 空间,属性为 normal,cache 的属性为 write-back,即仅更新cache,在合适的时候(由 cache 策略决定或者软件强制更新)将数据更新到相应的SRAM 空间% W& l% Q; l1 z1 V+ [. {- n4 W 0x4000_0000~0x5FFFF_FFFF: 芯片内部的外设空间,属性为 device,这一版是外设寄存器所处的位置,对其读写的过程中不会经过 cache; O' d( p- ^; D% e1 g2 a7 k! W5 E XN 的意思是 Execute-Never,其含义为如果相应的地址空间是 XN,是绝不允许执行代码的。& w5 u( z0 s1 T/ W * b; B) V6 d+ ~4 Q Cache 相关函数及作用- D. s- s' ?7 I+ q# u 这里以 core_cm7.h 里对 cache 封装的函数为例7 ?4 o/ U" f8 v" l+ F6 t" C0 r% Q (C:\Program Files (x86)\IAR Systems\Embedded Workbench 7.2\arm\CMSIS\Include)0 o+ N2 h, F5 P$ u SCB_EnableDCache4 X* x- b x7 `$ U. l ## 使能 D-cache1 ~1 F/ j* q( T) P SCB_DisableDCache* A. {+ v$ A# Y ## 禁用 D-cache s! y4 a: Q6 n# {7 x ' b: D$ a! o4 ], i SCB_EnableICache ## 使能 I-cache% d+ e+ x5 _3 K6 F" ] SCB_DisableICache ## 禁用 I-cache SCB_CleanDCache1 M C3 c y* a2 X8 u7 B; E ## Clean 所有的 cache-line,即将 dirty 的 cache-line 全部写到 cache line 对应的真实的物理地址中所谓的 drity 属性,即写操作时,更新了相应的 cache-line,但是没有更新到真实的物理地址,而这个 clean 的动作,就是将 cache 中的内容更新到真实的物理地址中 ; }- B& R3 m5 o( u2 D) h SCB_CleanDCache_by_Addr' ?6 _; {1 _! x* v% e: e ## 根据地址信息 clean 其对应的 cache-line6 Y I6 C6 V. s/ C1 P+ s SCB_InvalidateDCache- c! C; O0 E5 {; P- s' m% o, n" V6 { ## 无效 D-cache,D-cache 被 invalidate 之后,当有 Host(如 core,DMA 等)读取数据时,会忽略相应的 cache-line 中的内容(因为被 validate 了),从真实的物理地址中去获取相应的数据: @6 q4 a: \+ B, i& T; ~ SCB_InvalidateDCache_by_Addr ## 根据地址信息无效其对应的 cache-line d6 X L$ |5 T& J/ V7 I Cache 一致性问题 P" b7 I- g# n7 p+ { 所谓的 Cache 一致性问题,主要指的是由于 D-cache 存在时,表现在有多个 Host(典型的如 MCU 的core,DMA 等)访问同一块内存时,由于数据会缓存在 D-cache 中而没有更新实际的物理内存。2 n* ], V- ^0 i& e1 L 第一种情况是当有写物理内存的指令时,core 会先去更新相应的 cache-line(Write-back 策略),在没有clean 的情况下,会导致其对应的实际物理内存中的数据并没有被更新,如果这个时候有其它的 Host(如 DMA)访问这段内存时,就会出现问题(由于实际物理内存并未被更新,和 D-cache 中的不一致),这就是所谓的 cache 一致性的问题! " n0 Q8 y: k, X+ L 第二种情况是 DMA 更新了某段物理内存(DMA 和 cache 直接没有直接通道),而这个时候 Core 再读取这段内存的时候,由于相对应地址的 cache-line 没有被 invalidate,导致 Core 读到的是 cache-line中的数据,而非被 DMA 更新过的实际物理内存的数据,下面这张图比较清晰的展示了上述两个过程:( a0 h) h: g+ O, @; O" j$ N 第一种情况 
# k# ^! i$ Q, d$ C 第二种情况( @( [5 n& c* C& ?9 n6 i KX_)JPA_IVP@ZO.png")
下面以一个实例来分析 cache 一致性问题,展示的是上面的第一种情况,如下图所示: H32VF.png")
先看一下这个例程数据的传输流程和路径: SRAM1_Buffer 先全部写入 0x55 Core 将 Flash 中的 Const_Buffer 写入 SRAM1_Buffer(这里会先经过 d-cache)2 ]4 f9 h; [0 t7 N! Q 配置 DMA,将 SRAM1_Buffer 中的数据通过 DMA 写入另一段内存 DTCM_Buffer 比较 DTCM_Buffer 中的数据和 Flash 中的 Const_Buffer 数据,看是否一致- k# N) f+ t: E4 d$ y : F7 G8 m2 E" ^7 ]& r # a: ?; _, i0 Y. d 代码示例如下:: _% L$ |, S6 m/ _8 C( |2 o MPU 对 memory 的配置 - - - - step1$ h, |! `( s4 c # v3 t3 \0 P8 H2 C9 p* P ![6WK1[R2A[OD)ON@T3SOZ]3C.png](data/attachment/forum/202202/26/162936rqsmhrqimsxwsor2.png "6WK1[R2A[OD)ON@T3SOZ]3C.png")
重点介绍一下高亮部分的配置:, D. X# g" i7 ~# N+ W! i% C BaseAddress 为要配置的存储空间的起始地址; Size 为要配置的存储空间的大小& C+ z$ T/ a: v# I! l7 r IsCacheable 表明这段存储空间是否可以 cache& N" O/ v, @# R0 Q IsBufferable 表明使能 cache 之后,策略是 write-through 还是 write-back(bufferable)5 P" h" M& R1 r/ o. H! G; w 这里需要特别注意的 1 点:配置的 BaseAddress 需要被 Size 整除,以上述配置为例,即0x20010000 除以 256K 需要是整数! " r# ?8 D, K1 {5 B6 | @7 g/ ^ 使能 Cache - - - - step2* |! s, c$ ^1 S7 `9 I+ E 8 D/ j: [, d& B 
初始化 SRAM1_Buffer 为 0x55 - - - - step3/ b; t+ N( O; ~1 K$ b6 y Copy Flash 中的 Const_Buffer 到 SRAM1_Buffer - - - - step4 配置 DMA,将 SRAM1_Buffer 写入 DTCM_Buffer - - - - step5" n6 I# F8 y1 e; ~" | O/ s/ f 比较 DTCM_Buffer 和 Const_Buffer,看是否一致 - - - - step67 }: t* p: C2 c+ Z 从结果上看,最后一步比较的结果并不一致,原因比较简单,由于设定的 WB 策略,所以在step4 的时候,数据会暂存在 D-cache 当中,并没有更新到 SRAM1_Buffer,所以当SRAM1_Buffer 被 DMA 拷到 DTCM_Buffer 中的时候,有一部分可能还是初始值,导致最终4 e& r5 P8 o# \) g; N2 v 的比较不一样,而解决的方法有以下几个: 1. MPU 配置的代码,将属性改为 MPU_ACCESS_BUFFERABLE,即使用 write-though 策略 2. 通过 cache 控制寄存器,将所有 cacheable 的空间全部强制 write-though1 j+ |% T0 l' l6 C 1 B+ [3 K; `/ d4 N6 t: E% R3 `" o7 E 
![6O@]V~V_51C]`5Q3]BK}N5O.png](data/attachment/forum/202202/26/162936fcl8wtwfthd0ca0c.png "6O@]V~V_51C]`5Q3]BK}N5O.png")
& D: }0 a8 J: p: K1 ~+ v 3. 将 dirty cache-line 更新到真实的物理地址中 在 step5 操作之前,先调用 SCB_CleanDCache 或 SCB_CleanDCache_by_Addr 将相应 cache-line 中的数据写入 SRAM1_Buffer,就解决了这个问题! 5 D( Z3 b7 I/ B- w1 t6 s- _ 这是最常用的方法,在实际的开发过程中,为了提高性能,一般都会使能 cache,同时将其配置为 WB策略,这就需要开发者在使用时特别小心!同样如之前的第二种情况,需要先调用SCB_InvalidateDCache 或 SCB_InvalidateDCache_by_Addr 去 Invalidate 相应的 cache-line,这样当core 在读取时,会忽略 D-cache 中的内容,去真实的物理地址读取对应的数据! 8 n" C+ C4 h1 Q* m3 @* S7 P |
【实战经验】基于STM32F7的网络时间同步例程
STM32硬件结构学习
STM32中BOOT的作用
【STM32F769I-DISC1】开发板刷入Micropython并完成点灯、读取内部温度测试
【STM32F769I-DISC1】测评01:创建STM32cube IDE 工程,点个灯
【STM32F769】创建deepseek本地服务,并实现http请求
汇编浮点库qfplib移植STM32F769I-DISCO开发板与硬件浮点运算性能测试对比
coremark移植到STM32F769I-DISCO开发板的两种方法
【GUI板免费申请活动】【圣诞GUI】使用F746-DISO基于TouchGFX的圣诞树
刘氓兔的杂谈【001】-片上USB 高速PHY
 微信公众号
微信公众号
 手机版
手机版