.png) STMCU小助手
发布时间:2022-8-3 00:19
STMCU小助手
发布时间:2022-8-3 00:19
|
前言 本文会从结构,原理以及应用方面对 MPU 和 Cache 进行分析,主要目的是希望读者对 Cache 有基本的了解,在具体的实际应用中,使用带有一级 cache 的 MCU 时,避免常见的错误。 Cache 介绍 Cache 及其原理 Cache,高速缓存,一般指的是 L1 cache,即和 Core 紧耦合的,从 STM32F7 系列开始,基于 ARM cortex-M7 内核,增加了对 L1 Cache 的支持。 F5HC1.png")
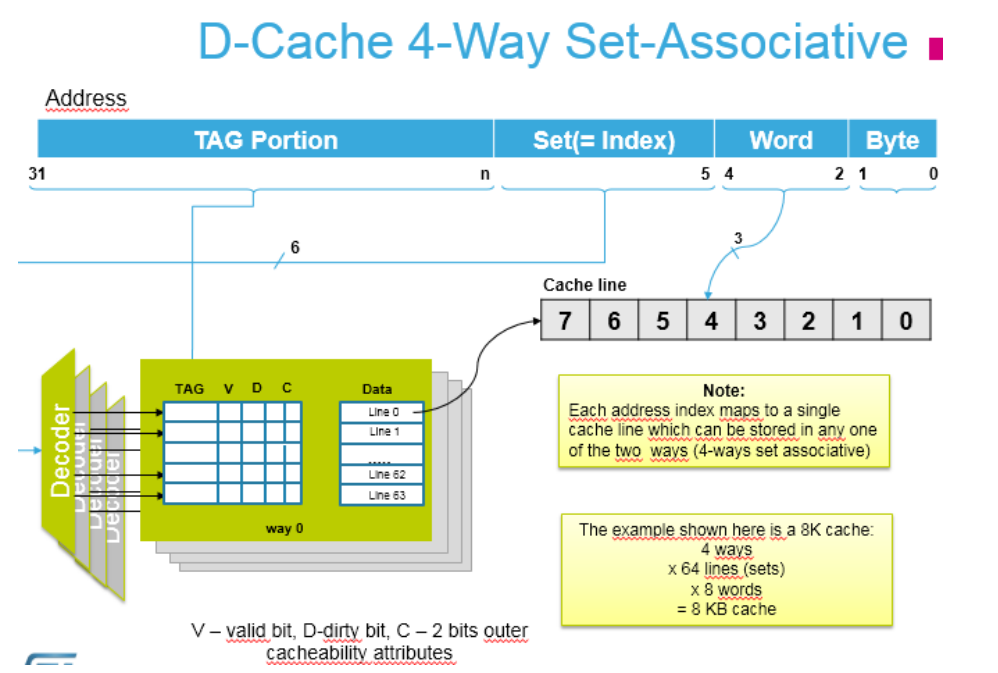
从这张图片可以看出来,无论是指令 Cache(I-cache)还是数据 Cache(D-cache),一旦使能之后,就分别与 Core 的 prefetch unit(I-cache)和 load-store unit(D-cache)相连,以 D-cache 为例,因为直接与 LSU 相连,访问速度会比直接访问 SRAM 或外部 RAM 快很多,只要保证 cache 有足够高的命中率(由 cache 策略保证),尽量少的 cache miss,读/写的速度会有比较大的提高。 结构及策略 同样这里以 D-cache 为例,看一下 D-cache 的构成: 
包括 Address 和 cache-line,Address 表明其地址,对应一条包含 32bytes 的 cache-line: 读数据时,当地址命中时即 cache-hit,便可以直接从 cache line 中取出相应的数据,反之,当遍历了address 都没有找到,就会产生 cache-miss,这时便会从实际的内存单元(如 SRAM)中取出相应的数据, 并更新到某一条 cache-line 中并修改相应的 cache-line 信息; 写数据时,就有点不同了,包括 write-through 策略和 write-back 策略,当使用 write-though 策略时,更新 cache-line 的同时,同样会更新其对应的实际物理地址的区域,当采用 write-back 策略时,更新cache-line 的同时,并不是马上去更新其对应的实际物理地址的内容,而是在其认为合适或者所有的cache-line 都 dirty 的时候才会去更新,当然,也可以通过软件让其强制更新,即 clean 的动作,这一块会在后面的 cache 一致性问题上也会有体现;同样,对于为什么将 cache 拆分为 2-way 或是 4-way,这和 cache 自身的策略如查找算法等相关,由于本文侧重讨论 cache 的应用相关问题,所以关于 cache 本身的策略这里不再详述。 Cache 及 MPU 属性 这里需要注意的是,cache 一般是配合 MPU(memory protection unit)一起使用的,首先需要通过 MPU配置相应 memory 的属性(normal, strongly-ordered, device, XN etc.),如下表所示: [[Y2B2R.png")
选取几个有特点的作为示例: 0~0x1FFF_FFFF: flash 空间,属性为 normal,cache 的属性为 Write-through,即更新 cache 的同时,将数据同时写入相应的物理地址空间0x2000_0000~0x3FFF_FFFF: SRAM 空间,属性为 normal,cache 的属性为 write-back,即仅更新cache,在合适的时候(由 cache 策略决定或者软件强制更新)将数据更新到相应的SRAM 空间0x4000_0000~0x5FFFF_FFFF: 芯片内部的外设空间,属性为 device,这一版是外设寄存器所处的位置,对其读写的过程中不会经过 cacheXN 的意思是 Execute-Never,其含义为如果相应的地址空间是 XN,是绝不允许执行代码的。 完整版请查看:附件 |

STM32F7 MPU Cache浅析.pdf
下载530.93 KB, 下载次数: 9
STM32F745 USART1 Bootloader启动失败排查与解决的流程分析
STM32芯片命名规则
STM32 引脚到底有多少?为什么一个引脚能当好几个用?
入门嵌入式,为什么STM32是“优选起步”?
嵌入式-单片机-STM32 EXTI中断
STM32单片机进行除零运算,为何程序不崩溃?
STM32 LL为什么比HAL高效?
STM32时钟详解
2025国庆中秋活动体验报告2——TouchGFX的UI设计
2025国庆中秋活动体验报告1——TouchGFX环境配置
 微信公众号
微信公众号
 手机版
手机版