.png) STMCU小助手
发布时间:2022-12-8 16:00
STMCU小助手
发布时间:2022-12-8 16:00
|
多年来,大多数基于微处理器的小型系统通常都没有使用缓存,随着 ARMv7 架构的推出,缓存技术在 ARMv7- A家族中得到了支持(例如 Cortex-A8 等微处理器内核),但在诸如 Cortex-M3 和 Cortex-M4 等 ARMv7- M 等微控制器内核设计中都还不支持缓存。然而,当 Cortex-M7 发布时,它打破了这一状况,使得在更小的嵌入式微控制器上也能够支持缓存。本系列介绍分为以下三个部分:
缓存的目的是提高内存访问的平均速度,最直接和最明显的好处是应用程序性能的提高,这反过来又可以导致功耗模型的增强。缓存已经在基于处理器的高端系统中使用了很多年(可以追溯到20世纪60年代)。 缓存的开发和使用背后的驱动程序是基于 Cache 局部性原理的,缓存的工作基于两个局部性原则:
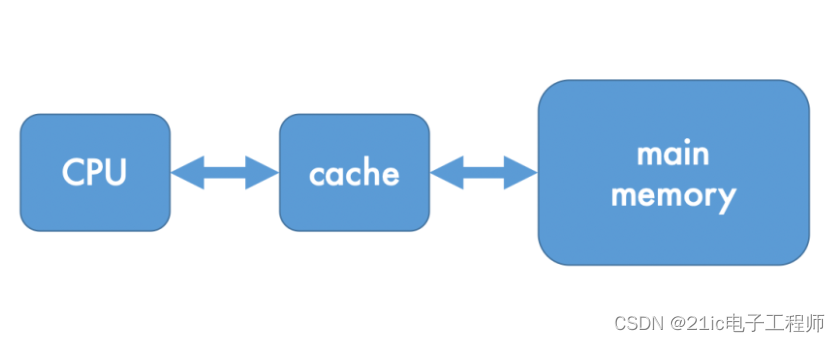
同样值得注意的是顺序性——如果引用了一个特定的位置,那么很可能在接下来的几次访问中,会访问 s + 1 的位置。序列性是空间局部性的一种受限类型,可视为空间局部性的一个子集。 在高端现代系统中,可以有多种形式的缓存,包括网络和磁盘缓存,但这里我们将重点介绍主存缓存。此外,主存缓存也可以是分层的,即处理器和主存之间有多个缓存,通常也称为 L1、L2、L3 等,其中 L1 最靠近处理器核心。 ! l# u; s* @1 [1 p! v7 k缓存定义 最简单的理解方法是将缓存看作位于中央处理器单元(CPU)和主存之间的小型高速缓冲区,用于存储最近被访问的主存块。
一旦我们使用了缓存,每次读取内存都会导致以下两个结果之一:
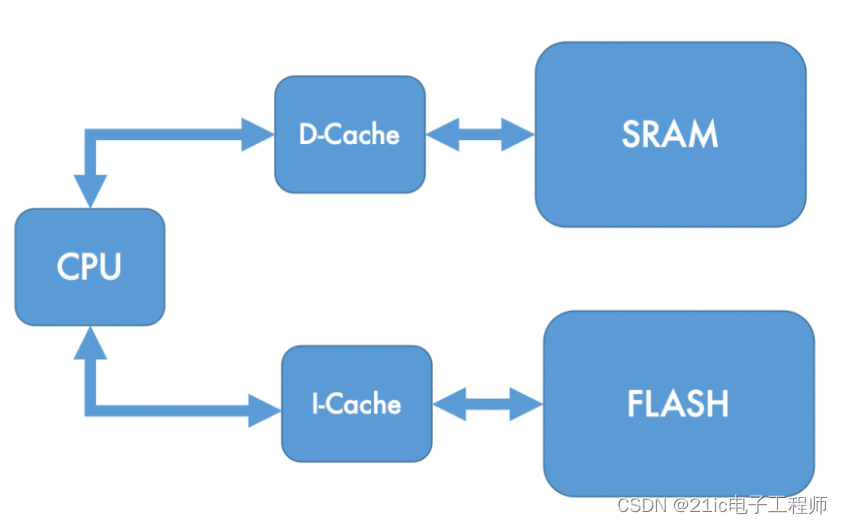
核心处理器体系结构通常将驱动支持的缓存实现。我们熟悉的有两个主要的架构,哈佛和冯·诺依曼。冯·诺依曼体系结构只有一个总线,用于数据传输和指令获取,因此不同的获取必须交错进行,因为它们不能同时执行。哈佛体系结构有独立的指令总线和数据总线,允许在这两个总线上同时执行传输。 冯·诺依曼体系结构通常有一个统一的缓存,它同时存储指令和数据。因为哈佛的体系结构有独立的指令和数据总线,所以逻辑上它们通常有单独的指令和数据缓存。
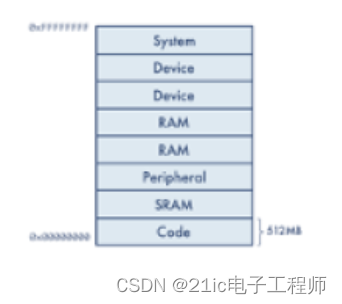
Cortex-M7 是哈佛体系结构的一个变体,被称为改良的哈佛架构。像哈佛体系结构一样,它提供独立的指令和数据总线,但这些总线访问统一的内存空间,允许像访问数据空间一样访问指令内存的内容,这意味着修改后的哈佛架构可以同时支持统一的和独立的缓存。 同样值得注意的是,ARMv7-M 系列核心都是基于加载/存储体系结构的。值得注意的是,这意味着唯一允许的数据内存访问是通过加载和存储操作(LDR/STR),所有算法数据操作都是使用通用寄存器(r0-r12)执行的。 - s) }: ? T# x- m1 qCortex-M4 / Cortex-M7 内存系统 与其他 ARM 系列不同,ARMv7-M 架构将内存映射预先划分为 8 x 512MB 的部分,然后分配给代码、RAM、外设和系统空间。
Cortex-M4 和 Cortex-M7 共享相同的系统内存映射,但具有完全不同的内存系统。在 Cortex-M4 上,你可能会看到片上 Flash 位于地址 0x00000000,片上 SRAM 位于地址 0x20000000。然而,在 Cortex-M7 上指令和数据地址区域都会有两个不同之处。 正如预期的那样,我们现在有局部的(L1)指令(I-Cache)和数据(D-Cache)缓存。Cortex-M7 内存系统还包括对本地紧密耦合内存(TCM)连接的支持,用于指令和数据,分别称为 ITCM 和 DTCM。 + g) O; ?' m2 P+ T+ F" ~缓存基础知识 如前所述,我们的缓存是主存和中央处理器之间的本地高速缓冲区。在 ARM Thumb-2 ISA(指令集架构)中,加载和存储操作可以在内存中传输字节、半字(2字节)或字(4字节)。但是由于空间局部性,缓存控制器不是将单个读取缓冲到某个位置,而是在当前访问的内存周围输入一些字数据。从主存到高速缓存的单次传输的字数称为高速缓存行长度,将数据读入高速缓存的过程称为行填充。行长度因设计而异,但在 Cortex-M7 上固定为 8 个字(32字节)。 由于内存访问的原因,每个缓存线现在都由一个 32 字节的边界地址限定。因此,从地址 0x0000000c 读取的内存与地址 0x00000018 在同一条缓存线上。
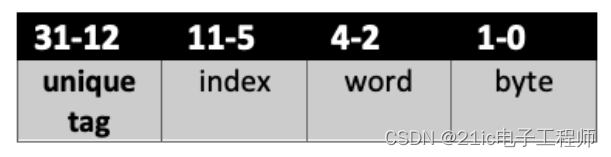
这意味着,对于一个 8 字缓存线,如果我们屏蔽了底部的 5 位,那么同一缓存线中的所有地址将得到相同的结果。如果我们现在将结果右移 5 位,我们将得到每个地址的唯一索引(例如(address & ~0x1f)>>5))。 在剩下的底部 5 位中,比特位 4-2 索引到缓存线内的字,比特位 1-0 为字内的字节(当需要字节和半字访问时)。
因此,从 0x0000004c 读取的字偏移量与 0x0000000c 相同,但位于不同的缓存线索引中,0x00000078 和0x00000018 这一组也是如此。
当然,这个模型只有在我们的缓存大小与 Flash/SRAM 相同的情况下才会工作,这在某种程度上破坏了对象(并且不具有成本效益)。因此,缓存的大小将明显小于可用的 Flash/SRAM,所以我们现在需要修改索引模型。 Cortex-M7 上的缓存是可选的,但假设支持它,缓存大小可以是4KB、8KB、16KB、32KB或64KB。注意,指令和数据缓存的大小可能不同。 假设我们有最小的可用缓存大小(4KB),然后我们可以计算独立缓存线的数量。对于一个 8 字的缓存线,这给我们留下了 128 个唯一的缓存线集合,因此索引 [0-127] 有 7 个比特位。
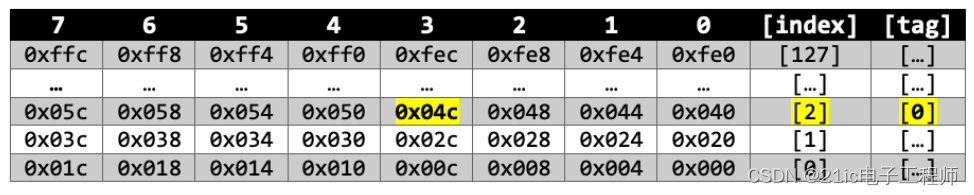
为了计算地址的索引,我们简单地屏蔽 bit11-5 位并右移 5 位 ((address & 0xfe0)>>5)。然而这意味着,在一个典型的 Flash 地址范围内,多个地址将映射到相同的索引,例如: (0x0000004c & 0xFe0) >> 5 = index 2, word 3 (0x0000204c & 0xFe0) >> 5 = index 2, word 3 因此,如果我们读取了地址 0x0000004c,那么缓存控制器将用地址 0x00000040-0x0000005f 的数据字节去填充第2个缓存行。除了存储的内存值之外,缓存控制器还会将地址标记与行号一起存储。标记是地址的剩余部分(例如(address & ~0xfe0) >> 12)。
于是针对我们的两个地址,我们可以做以下标记: 0x0000004c : index 2, word 3, tag 0 0x0000204c : index 2, word 3, tag 2 如果我们随后从不同的地址,比如 0x0000204c 读取,这将匹配相同的缓存索引。但是缓存控制器也比较缓存行地址标记与实际地址标记的地址标记,这当然不匹配,从而确保缓存控制器不会将缓存中的内存返回给处理器。当标记不匹配时,这被称为缓存未命中,在这种情况下,我们需要一个切实的处理规划来面对缓存缺失——也可以称之为策略。 |
STM32H745I-DISCO脉冲宽度调制(PWM)
STM32H745I-DISCO串口通信,输入输出
拷打cubemx【002】——自定义还需基于芯片的工程
STM32硬件结构学习
STM32中BOOT的作用
STM32H7的TCM,SRAM等五块内存基础知识
STM32H7的TCM,SRAM等五块内存基础知识
简单了解一下STM32H7的BDMA
有奖预约 | STM32H7R7基于RT-Thread RTOS的智能终端GUI解决方案
【STM32H745I-DISCO】基于TouchGFX的工业控制器界面设计
 微信公众号
微信公众号
 手机版
手机版