1 h# P; x$ Y& o' B" x+ {4 `3 G. z
01引言9 F2 T7 i& ^7 V* L) T! l1 v3 K( D' }0 p
客户在使用 STM32G474 时,希望使用 FPU 进行浮点运算,并最大化其性能。本文 从 STM32G474 系统的角度、ARM DSP Lib、编译选项的影响等几个方面探讨如何提升整体性能,并介绍如何使用 KEIL 工具进行测量。
. t0 z$ N' _& O M) O* C1 p. L
7 @$ W0 F% Y% h02STM32G474 FPU 运算性能优化 ; S# ^ t* q( a# P3 b
2.1. STM32G474 系统性能优化 % l. i/ F' U; P9 [- \
3 U: e! |/ U+ p3 X. g
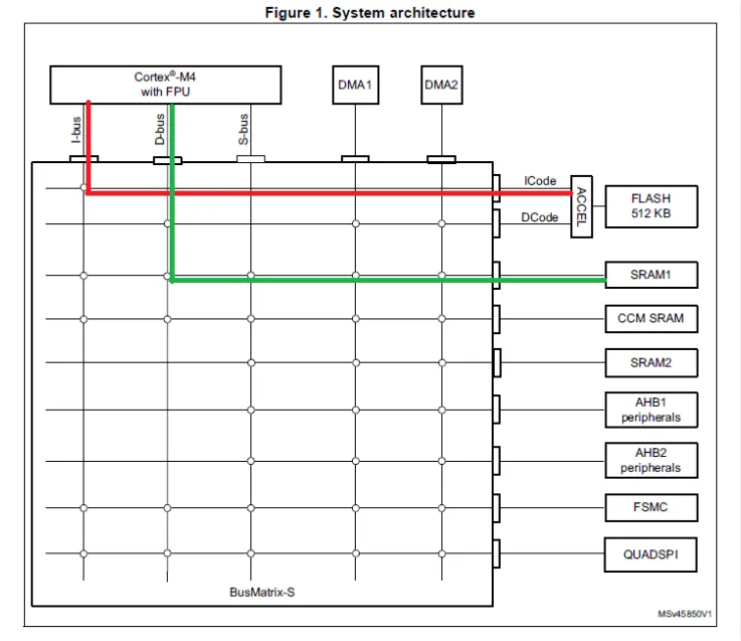
STM32G474 使用的是 ARM Cortex-M4 内核(+FPU)。一般代码会放在 FLASH 区, 通过 I-Bus 读取。这里 STM32G474 有 FLASH 预取指及 CACHE Line, 无需放入 IRAM 或 CCM。因为 Cortex-M4 DSP 指令中没有运算指令与加载指令并行的混合指令,所以数据 存放区域及 Bus 的选择理论上对性能的影响不大。如下图 1 所示,可将 FPU 运算数据放 在 SRAM1。另外还需尽量避免 SRAM 的并发访问,如使能了 DMA,DMA 传输目的地 可以使用 SRAM2,从而减少潜在的 SRAM 并发访问产生的性能下降。应用则需要根据实 际情况,合理使用内存区域。( e9 }' R; W H8 u1 X/ X
▲ 图1. STM32G474 架构 ' H( I8 b+ U7 j- X- i
/ P" V- ^* I: Y! w9 g
2.2. ARM DSP Lib 的使用
$ X2 [ X# j& o+ H在 ARM DSP 库实现了很多 math 算法,可进行浮点乘加、点积、卷积、FFT、NN 等 多种算法 API,可以使用 ARM DSP 库高效使用 FPU。ARM DSP 代码位置如下:
) E% E/ o7 @9 E0 p
. P8 d: H; w: k# v0 I2.3. 示例代码 ' f* a* E# ~! ~* W! n
下面示例代码中对浮点乘法运算进行了测试。用户可以使用 STM32CubeMX 生成 STM32G474 KEIL 工程,在 main.c 文件中加入如下示例代码:
! \5 j; S8 K4 t" l( k+ T a& v
: ]( R) e5 @) E- __attribute__((section (".TEST_INPUT_A"))) float32_t testInputA[1024] =
+ q5 W$ C( I' \% ]/ C - {
5 _3 y" X: Q+ P$ T6 A' {4 d: P - 0.623234f, 0.799049f, 0.940890f, -0.992092f, 0.212035f, 0.237882f, -) h; Q1 j! d# m4 r3 r
- 1.007763f, -0.742045f,( M( L3 r+ T2 z- g9 k5 C# j
- ~~ 这里数组使用动态生成的float数据,数据量较大,略1 {1 E s8 c& \1 w
- -0.417470f, -0.205806f, -0.174323f, 0.217577f, 1.684295f, 0.119528f,
0 H' _1 ?4 T& r0 L: k- s: R - 0.650667f, 2.080061f7 W# |+ {1 {: ^8 s9 D
- };: D& Z9 n* B& ~8 _
- __attribute__((section (".TEST_INPUT_B"))) float32_t testInputB[1024] =
" M2 z7 a8 q* z; T7 }9 \/ w9 K - {
2 B+ _; a/ ]" m* L2 a) `1 g: |+ Y5 C - -2.423957f, -0.223831f, 0.058070f, -0.424614f, -0.202918f, -1.513077f, -: ~$ S- R7 y" l
- 1.126352f, -0.815002f,/ U1 x$ g; B9 c( N
" w1 T# d5 a% m X. y- ~~ 这里数组使用动态生成的float数据,数据量较大,略 " `9 ^: j, B# X H6 n% m9 ^
- -0.447001f, -0.725993f, 0.354045f, -0.506772f, -2.103747f, -0.664684f, 1.450110f, -0.329805f . B2 c* b9 C8 w4 N+ B: i' P
- };
% T; J# Q# n, b. Q* q
5 Q' O. D+ o1 c' i5 |% M4 E- __attribute__((section (".TEST_RESULT_D"))) float32_t testResult[1024]; 3 Q$ y" y' y' Z5 c; M& R# V
' ^. i& i) b% p1 ? F- float32_t* pA;( Z: Q5 N% F1 B; u9 ^% g- I
- float32_t* pB; ) X6 p; Z+ l" d9 m
- float32_t* pR; # }* f X; A- h/ }* O, d
- /* Private user code --------------------------------------------------*/ & c9 b6 [! H2 n: d Z0 T5 X
- /* USER CODE BEGIN 0 */
. e$ |( n) t: ? - void test_normal_mul(uint32_t kLoops, float32_t*
! j5 `# A! y+ [; A' L+ U& d$ \/ | - pSrcA, float32_t* pSrcB, float32_t* ' j" V6 }; H) T0 v6 v! M
- pResult, uint32_t lenVector) 1 N. ^' Y/ L6 ^) Z; J6 ?7 G0 \
- {
/ R6 f: u Y$ b) U - for (uint32_t j = 0; j < kLoops; j++) - B- M9 U' K* g& Q' P. X% p$ |
- {
9 X r+ b) \8 S% E* i4 x8 W7 c - pA = pSrcA; + _" X& z- E$ E/ t( G% b: C( f
- pB = pSrcB; ^3 \& k; b* @) I
- pR = pResult; 6 C o- R9 y: [! c
- % b; u( i. h8 C) P
- for (uint32_t i = 0; i < lenVector; i++) 0 F: l$ C8 z" V; X0 ~
- { *pR++ = (*pA++) * (*pB++) ; ! D4 q% k; L5 j& W
- } 2 t8 [8 t6 O! s9 Q. w
- }
& K. R* O8 a8 C6 {4 } - }
6 i) Y, I5 R4 J4 A9 Z# i' b - / J& F4 d/ F" [+ b5 m; D3 [8 F
- #if defined (__FPU_USED) && (__FPU_USED == 1U) : ?* C, e' {% K$ l8 Q3 p* p
- /* Use arm dsp lib to test basic operation Multiply, FPU enabled */
* T: P) ]$ o- `! J2 c - void test_arm_math_mul(uint32_t kLoops, float32_t* pSrcA, float32_t* pSrcB, float32_t* / E( @$ e0 @. M7 S1 F
- pResult, uint32_t lenVector) 8 U% @4 T$ `8 }
- { , P- z T5 L- r8 F1 I2 Z
- for (uint32_t j = 0; j < kLoops; j++)
2 @. y. L6 ^3 n1 Y5 q - { 8 d* `/ Y% J2 \
- pA = pSrcA; //Code alignment with the function without FPU # E: t: J- V) b$ N) i3 L
- pB = pSrcB;
% f0 [9 ]7 e9 V - pR = pResult;1 ^2 r4 d- o7 }+ J8 M1 F$ j8 y
- arm_mult_f32(pA, pB, pR, lenVector);
, m3 p/ E3 a$ U& y; A2 _- { - }
8 A" Z0 R3 u- B8 n - } & ^3 y. L% G/ h1 ~
- #endif ) I& E* J! t) P7 p3 Z
- 0 b! @9 e3 h' M$ b, w- X% t
- /**
1 c9 D6 X- R' ]3 L - * @brief The application entry point. 8 v9 D7 A" I( N/ P3 j2 ~, E: [8 a
- * @retval int
) m) z9 o N+ y# O+ a7 v8 W( | - */ 6 z5 V$ N& `1 V8 g+ O
- int main(void) ' O) c2 |: D1 Z S7 o
- {
/ s/ g9 \/ ]% @+ |6 l( R- _ - /* MCU Configuration------------------------------------------------*/
% X. s4 C4 ^5 a0 g: O- t
2 p" T8 l8 G, }' D# A- /* Reset of all peripherals, Initializes the Flash interface and the Systick. */ % N- x4 L8 g: I/ R# X1 [' ]' u
- HAL_Init();
1 Y4 J8 f/ C. R+ X; ]9 l* s6 G- h8 r
+ X) ]3 V T4 q# _- /* Configure the system clock */ * ]2 T' t- j; M
- SystemClock_Config();
+ l/ z/ T! [1 A$ a1 k
3 X: {7 \* S% f5 l; M1 j( r* e- …
7 G( I% m/ x/ y- A0 ]1 E& ^ - " M4 L" O7 z; x9 P, \+ S4 ?$ a
- HAL_Delay(100);
: f# U& ~8 {$ o# U; @: h - 5 u5 h9 v: |# \: G3 Q1 i o% z
- /* USER CODE BEGIN 2 */
4 G1 S1 u3 ?( ^) R; y1 t - test_normal_mul(10, testInputA, testInputB, testResult, 1024);
. D7 s, Z8 d3 k% T( n4 I - test_normal_mul(10, testInputA, testInputB, testResult, 1024); - h( \9 i2 }: \1 C% L
3 I. I/ N+ ^$ {/ g- r( T0 \1 \- #if defined (__FPU_USED) && (__FPU_USED == 1U) 5 x! R3 }: w( m
- // Multiply calculation with arm dsp lib $ q: v. T& X; Z. E' A
- test_arm_math_mul(10, testInputA, testInputB, testResult, 1024);
( z+ F3 q0 T9 v# T2 A - test_arm_math_mul(10, testInputA, testInputB, testResult, 1024);
1 C' C& O1 N% ?1 T& [3 p. Y R; W - #endif 0 O- X& x1 ^3 Z& H- q
& M* x6 m& D; ]+ h" A9 O- /* USER CODE END 2 */
6 L, C0 Y' @% i1 o
) r L: `8 {, O: b( p" I- /* Infinite loop */ 5 g+ ^4 Z" U1 C0 b- D" U' O
- /* USER CODE BEGIN WHILE */ 4 Q% U2 f/ i, B/ z$ q
- while (1) / L0 F+ ^& x( g% R
- {2 _) ~8 d5 W, c$ V* @
- /* USER CODE END WHILE */
t/ W% ?$ C0 k( [, p2 c
# W% \9 m2 o, X; P3 j5 D) v- /* USER CODE BEGIN 3 */ 1 X* O0 P, A0 h) M4 q
- }
3 @$ i1 }: U$ f' J6 C3 \ - /* USER CODE END 3 */
. t0 e# E6 T% o z* z - }
2 P" q G$ H% {4 n, d通过 KEIL 工程 Options / Target, Floating Point Hardware, 确定 FPU On/Off。
8 |0 t1 E4 Y6 D* R
* B! D) B3 i$ M+ z" P5 Y+ d6 C& E! i$ n% [% d
▲ 图3. KEIL 项目工程 FPU 单精度浮点设置 通过 STM32G474_FPU_TEST.sct 文件配置 Data 存放区域,如下例,将测试数据置 于 SRAM2。) `( Q4 y, k1 p1 ~9 Z' y
- 2 ~- U5 o0 C* d7 e( S8 C2 J
- RW_IRAM1 0x20000000 0x00014000 { ; RW data3 u6 D8 c+ m; l
- .ANY (+RW +ZI)3 j- v" S+ S& y% Q) {1 D+ [
- }
5 p o5 {" m+ \( T - RW_IRAM2 0x20014000 0x00004000 {
$ ^6 q& [$ z+ B- o `5 ^" h - *(.TEST_INPUT_A) G; B- S3 ^4 B3 M, g
- *(.TEST_INPUT_B)
% z! E, o- o9 ? - *(.TEST_RESULT_D)- O6 @& y" f; C5 u8 I; K
- }
, {- f5 V1 G' B. F, F4 n1 M) X3 E; ~& M - RW_CCM 0x20018000 0x00008000 {' L* V5 i7 o: ~: C) E. q
- }
0 s/ N v" V2 k3 U# T
% o- g7 J. E3 [: D( h( Y2.5. 编译选项
) y$ n1 Y) c. n* W本文中我们使用的是 KEIL IDE,设置使用的是 KEIL Compiler V5。为了获得代码最 大程度上优化,我们使用了-O3 优化选项,与-Otime(Optimize for Time)结合使用。该组合选项意味着会进行更多代码优化,如循环展开,更激进的函数内联和自动函数内联 (-O3 默认使用--autoinline)等,当然副作用是二进制代码大小会有所增加。另外,增 加设置 --loop_optimization_level=2 来控制循环展开的优化等级。(注意:-- loop_optimization_level=2 选项只能与-O3 -Otime 一起使用。)如果您对 FPU 架构比 较熟悉,也可以尝试增加—fpu=fpv4-sp(Cortex-M4F FPU 实现的是 FPv4-SP 浮点运 算扩展)等选项,不过一般使用默认即可。/ S% H4 X* Q9 J. U0 E
▲ 图4. KEIL 工程,编译选项设置 03使用 KEIL Trace 工具进行测量
7 Y0 @- v5 k- ^) a; m8 ^/ Z; |7 P3.1. KEIL 工程设置
. V' i! t+ h# @- e0 K1 t D. m0 u" a, s, I
KEIL 工程下,首先选择工程选项设置,在 Debug 选项页中,右上部使用 Debugger 工具栏中选 Settings,如下图 5 和图 6 设置。注意 KEIL Trace 设置的时钟必须要与实际 STM32 使用的系统时钟相一致,如图 6 中,STM32G474 使用了 170MHz 的系统时钟, KEIL Trace 中也要相应设置为 170MHz。' }2 q2 r" G" L2 E6 a
▲ 图5. KEIL 工程,Debugger 设置入口 ▲ 图6. KEIL 工程,Cortex-M Trace 功能设置 运行KEIL debugger,如下图7所示,将断点设置在要测量的语句前及其后,执行 代码,当Debugger停在断点时,其状态栏中t1指示的即为当前代码的已执行时间。测试代码起止时间差即为代码执行用时。该Trace功能计时是比较准确的。当然如果您希望掌控更多,也可以通过代码来实现,如增加诸如如下代码:! j+ J% {5 T! ~' T" Q
nStart = DWT->CYCCNT;
8 D5 k7 Z" R8 w1 v~~~需测试执行时间的代码~~~ 1 h/ v* ?) ?/ I8 A
nStop = DWT->CYCCNT;
3 \1 d; h2 `9 L, b. Q: a% X然后用(nStop – nStart)/系统时钟,换算成时间即可。(我们这里没有考虑中断,一 般测量前需要禁用中断)
: }) z) M, }9 Q( q; D, l▲ 图7. KEIL 工程,Debug 模式下 Trace 程序执行时间 3.2. 测试结果
- m8 ?. u4 `, _+ _/ j4 W下表列出了STM32G474 10K次 浮点“乘”用时统计。
" K3 E7 I5 `/ O/ f6 n5 x▲ 表1. STM32G474 10K 次 浮点“乘”用时统计表 10 X 1024次浮点乘' V" S8 ~) v7 F
1 F; q# W8 ^- b
增加--loop_optimization_level=2 编译选项! T* U* z* a7 [* @! r
+ `; Q3 q7 d" ~FPU 核心汇编代码的比较,见图8和图9。
6 f$ W# m n7 |) P: e▲ 图8. 使用--loop_optimization_level=2 编译选项的常规代码汇编 ▲ 图9. ARM DSP 库 arm_mult_f32 函数汇编
R# \# p' v h* L
0 S* o! w0 i0 D$ d; o3 H使用loop_optimization_level=2, 常规代码使用KEIL compiler V5编译结果与 arm DSP Lib 的核心汇编基本相同。如果不使用loop_optimization_level=2编译选项, 则可以看到其主要区别在于KEIL Compiler V5 与ARM库对loop的unroll 处理程度不 同。在实际应用时,需要根据应用自身需求判断是否需要使用ARM DSP Lib,基本上 ARM DSP Lib是很高效的。
I+ b0 j( A) n$ G( M, F6 k- P( C2 h$ ^+ Q$ k+ p3 G/ r5 e! t, d& M
04小结 ( j1 k# T P0 S5 C2 U+ |( Y
本文介绍了使用 STM32G474 FPU 进行浮点运算,从系统的角度、ARM DSP Lib、 编译选项的影响等几个方面探讨如何提升整体性能,并介绍了如何利用 KEIL Trace 工具进 行测量。以供在系统性能方面有需求的客户参考借鉴。+ @/ F3 G9 W8 U: y
/ a& C+ z6 O2 }6 G! r3 y0 H

h6 h- k6 H5 v4 f" k! F7 j如果你有其他想要的实战笔记,可评论区留言,管管来跟工程师沟通!5 T$ \0 \1 a3 v4 E$ W
( l6 I" ]# b% k0 r9 n: Y4 t1 g5 W" o9 O0 B" r9 t0 B
8 S# b5 q9 \: _1 E$ M$ Y$ {( y$ n% x% B
) S6 e0 O/ R, A. l6 c4 A4 v) _
+ F" P# W% c6 X# d
: e( j, G0 X" F |4 J+ p ^% c/ ^9 P! f
. ]0 u2 _& N2 z9 q6 \! k4 }% j" E: G3 \4 w) k7 S/ x( M& c
6 a) B. K/ I+ g; j: K7 ^
- u1 U* Z' @4 ^& A$ N# X& R/ \- b) k' _# g( q% U I
|
 STMCU-管管
发布时间:2024-10-30 16:57
STMCU-管管
发布时间:2024-10-30 16:57










 微信公众号
微信公众号
 手机版
手机版