STMCU-管管
发布时间:2024-10-30 16:57
STMCU-管管
发布时间:2024-10-30 16:57
|
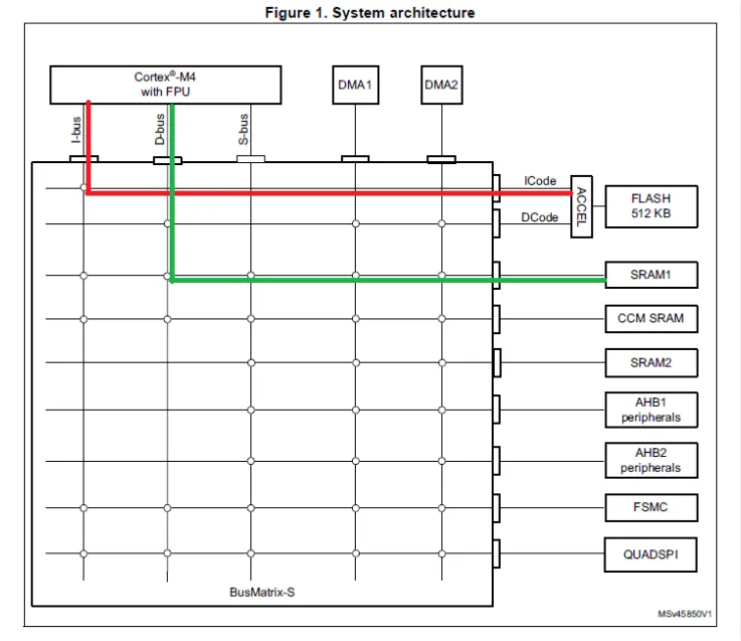
01引言 客户在使用 STM32G474 时,希望使用 FPU 进行浮点运算,并最大化其性能。本文 从 STM32G474 系统的角度、ARM DSP Lib、编译选项的影响等几个方面探讨如何提升整体性能,并介绍如何使用 KEIL 工具进行测量。 02STM32G474 FPU 运算性能优化 2.1. STM32G474 系统性能优化 STM32G474 使用的是 ARM Cortex-M4 内核(+FPU)。一般代码会放在 FLASH 区, 通过 I-Bus 读取。这里 STM32G474 有 FLASH 预取指及 CACHE Line, 无需放入 IRAM 或 CCM。因为 Cortex-M4 DSP 指令中没有运算指令与加载指令并行的混合指令,所以数据 存放区域及 Bus 的选择理论上对性能的影响不大。如下图 1 所示,可将 FPU 运算数据放 在 SRAM1。另外还需尽量避免 SRAM 的并发访问,如使能了 DMA,DMA 传输目的地 可以使用 SRAM2,从而减少潜在的 SRAM 并发访问产生的性能下降。应用则需要根据实 际情况,合理使用内存区域。 
▲ 图1. STM32G474 架构 2.2. ARM DSP Lib 的使用 在 ARM DSP 库实现了很多 math 算法,可进行浮点乘加、点积、卷积、FFT、NN 等 多种算法 API,可以使用 ARM DSP 库高效使用 FPU。ARM DSP 代码位置如下: 
2.3. 示例代码 下面示例代码中对浮点乘法运算进行了测试。用户可以使用 STM32CubeMX 生成 STM32G474 KEIL 工程,在 main.c 文件中加入如下示例代码:
通过 KEIL 工程 Options / Target, Floating Point Hardware, 确定 FPU On/Off。 
▲ 图3. KEIL 项目工程 FPU 单精度浮点设置 通过 STM32G474_FPU_TEST.sct 文件配置 Data 存放区域,如下例,将测试数据置 于 SRAM2。
2.5. 编译选项 本文中我们使用的是 KEIL IDE,设置使用的是 KEIL Compiler V5。为了获得代码最 大程度上优化,我们使用了-O3 优化选项,与-Otime(Optimize for Time)结合使用。该组合选项意味着会进行更多代码优化,如循环展开,更激进的函数内联和自动函数内联 (-O3 默认使用--autoinline)等,当然副作用是二进制代码大小会有所增加。另外,增 加设置 --loop_optimization_level=2 来控制循环展开的优化等级。(注意:-- loop_optimization_level=2 选项只能与-O3 -Otime 一起使用。)如果您对 FPU 架构比 较熟悉,也可以尝试增加—fpu=fpv4-sp(Cortex-M4F FPU 实现的是 FPv4-SP 浮点运 算扩展)等选项,不过一般使用默认即可。 
▲ 图4. KEIL 工程,编译选项设置 03使用 KEIL Trace 工具进行测量 3.1. KEIL 工程设置 KEIL 工程下,首先选择工程选项设置,在 Debug 选项页中,右上部使用 Debugger 工具栏中选 Settings,如下图 5 和图 6 设置。注意 KEIL Trace 设置的时钟必须要与实际 STM32 使用的系统时钟相一致,如图 6 中,STM32G474 使用了 170MHz 的系统时钟, KEIL Trace 中也要相应设置为 170MHz。 
▲ 图5. KEIL 工程,Debugger 设置入口 
▲ 图6. KEIL 工程,Cortex-M Trace 功能设置 运行KEIL debugger,如下图7所示,将断点设置在要测量的语句前及其后,执行 代码,当Debugger停在断点时,其状态栏中t1指示的即为当前代码的已执行时间。测试代码起止时间差即为代码执行用时。该Trace功能计时是比较准确的。当然如果您希望掌控更多,也可以通过代码来实现,如增加诸如如下代码:nStart = DWT->CYCCNT; ~~~需测试执行时间的代码~~~ nStop = DWT->CYCCNT; 然后用(nStop – nStart)/系统时钟,换算成时间即可。(我们这里没有考虑中断,一 般测量前需要禁用中断) 
▲ 图7. KEIL 工程,Debug 模式下 Trace 程序执行时间 3.2. 测试结果下表列出了STM32G474 10K次 浮点“乘”用时统计。 
▲ 表1. STM32G474 10K 次 浮点“乘”用时统计表 10 X 1024次浮点乘增加--loop_optimization_level=2 编译选项 FPU 核心汇编代码的比较,见图8和图9。 
▲ 图8. 使用--loop_optimization_level=2 编译选项的常规代码汇编 
▲ 图9. ARM DSP 库 arm_mult_f32 函数汇编 使用loop_optimization_level=2, 常规代码使用KEIL compiler V5编译结果与 arm DSP Lib 的核心汇编基本相同。如果不使用loop_optimization_level=2编译选项, 则可以看到其主要区别在于KEIL Compiler V5 与ARM库对loop的unroll 处理程度不 同。在实际应用时,需要根据应用自身需求判断是否需要使用ARM DSP Lib,基本上 ARM DSP Lib是很高效的。 04小结 本文介绍了使用 STM32G474 FPU 进行浮点运算,从系统的角度、ARM DSP Lib、 编译选项的影响等几个方面探讨如何提升整体性能,并介绍了如何利用 KEIL Trace 工具进 行测量。以供在系统性能方面有需求的客户参考借鉴。  如果你有其他想要的实战笔记,可评论区留言,管管来跟工程师沟通! |
ST全新高功率AI服务器电源设计学习记录
经验分享 | LAT1422 STM32 AFCI 方案 TensorBoard 的使用介绍
STM32 LAT实战经验资料汇总分享(260205)
我中奖啦,收到了STM32开发板,足足开心了一整天啊
STM32嵌入式常见面试知识点汇总
经验分享 | STM32 HRTIM实现复杂波形的配置演示
经验分享 | STM32G0 Stop模式下LPUART唤醒演示
经验分享 | STM32G4系列是否支持位带操作
经验分享 | 一段莫名的延时输出问题
经验分享 | 发不出去的hello问题
 微信公众号
微信公众号
 手机版
手机版