|
0 1 简介 STM32N6带有一颗600GOPS的NPU,不少客户工程师对如何在STM32N6上验证模型的准确率或者评估模型非常感兴趣。本文介绍ST官方提供的一种评估验证方法,对客户而言开发工作量较少,参考该方案的实现,可以非常方便地集成到自己的项目中。 0 2 环境准备 在开始介绍实验之前,需要准备好相应的开发环境,开发环境如下: 1.Python 3.9+ 2.最新的STM32CubeProgrammer 3.推荐使用STM32CubeIDE>=1.15.1或IAR>=9.40.1,需要安装STM32N6补丁,建议使用V9.40。 4.STM32N6的补丁在官方软件包SDK内,和其他STM32补丁包安装类似,本文未介绍安装方法,客户可自行参考相应文档。 5.开发板:推荐使用官方STM32N6-DK板,STM32N6-Nucleo板也可以,但由于没有外部RAM,测试会受限。 a. 安装完后,将stedgeai.exe的路径加入系统path环境变量。 b. 打开cmd shell,执行stedgeai--version,如果能看到下图信息则表示安装成功。
03 部署和测试模型
▲ 图1. 测试流程 测试流程如上图1所示:
3.1. 生成模型权重和代码 模型文件需要自己准备,也可以点击这里下载一个模型文件进行测试。 本文使用的模型文件来自: https://github.com/STMicroelectronics/stm32aimodelzoo/blob/main/image_classification/mobilenetv2/ST_pretrainedmodel_public_dat aset/flowers/mobilenet_v2_0.35_224_fft/mobilenet_v2_0.35_224_fft_int8.tflite 使用Windows命令行工具,进入模型所在目录,并调用: 运行成功后,在模型所在目录中会生成模型相关的内容,包括模型文件,权重文件,模型报告等。
▲ 图2. 模型文件夹中的生成内容 报告文件包含的信息比较丰富,主要包括以下几个部分:
▲ 图3. 报告总结 如上图3,报告总结中主要包含了输入输出的类型格式,flash和ram的占用信息。
▲ 图4. 内存占用情况 如上图4,主要列出了编译使用的选项,内存占用情况,本例中,主要使用了cpuRAM2,npuRAM5和外部flash。需要注意的是,npuRAM比cpuRAM对NPU而言访问速度更快。 内存的分配主要取决于一个文件,stm32n6.mpool,从上图可以看到它位于默认的安装目录,用户可以根据自己的需求和内存的实际情况对文件进行更改。 这条指令会用到两个默认的配置文件: 1.$STEDGEAI_CORE_DIR/Utilities/windows/targets/stm32/resources/neural_art.json. 2.$STEDGEAI_CORE_DIR/Utilities/windows/targets/stm32/resources/mpools/stm32n6.mpool. Note:$STEDGEAI_CORE_DIR表示默认的STEdgeAI安装目录,本文中后续还会使用该定义,均表示相同的目录,将不再提示。neural_art.json里面是一些编译选项,stm32n6.mpool里面是内存分配情况,分别表示编译器如何处理模型文件以及如何分配内存,后续还会详细介绍。
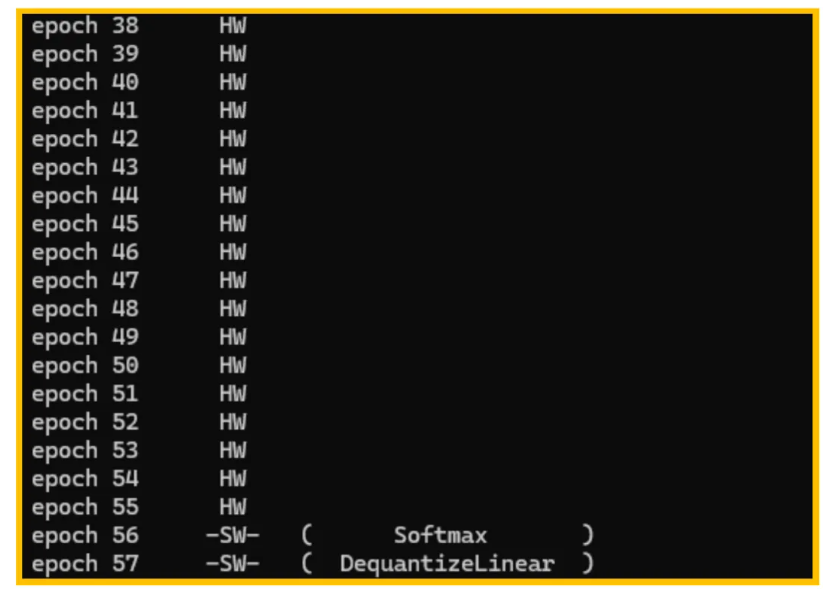
▲ 图5. Epoch情况part1
▲ 图6. Epoch情况Part2 图5、图6所示为Epoch情况,这里Epoch的概念是STM32N6编译器使用的概念,不是神经网络训练的epoch,每个epoch可以理解为NPU执行的一个最小的片段,神经网络会被切割为多个epoch,根据不同的神经网络,某些epoch可以被NPU执行,被称为HW epoch,某些无法被NPU执行,只能由Cortex-m55内核执行,这部分epoch被称为SW epoch。从上图可以看到只有2个epoch由软件实现,其余都由硬件实现,所以该模型的性能在STM32N6上是比较好的,如果有大量的epoch是软件epoch,则可能存在某些算子或结构无法被STM32N6的NPU实现,需要参考官方文档对算子进行修改。 3.2. 编译和下载 在调用脚本进行编译和下载之前需要确保以下内容是正确的: 1.$STEDGEAI_CORE_DIR/scripts/N6_scripts/config.json被正确配置:
▲ 图7. 配置文件 修改该脚本,确保上面用到的工具都能找到正确的路径。
a. 如下图8,运行命令,检测是否OK。
▲ 图8.检测objcopy工具
执行下面脚本(需要替换为STEdgeAI的安装目录): 脚本执行过程可能会遇到问题,例如下图9中所示权限不够情况:
▲ 图9. 执行失败 解决方法: 1.使用管理员权限重新打开 cmd shell后,重新执行。 2.将STEdgeAI安装到用户目录后,重新执行。
▲ 图10. 找不到文件 上图10“找不到文件”问题的解决方法:
▲ 图11. Loading memories failed 由于IAR版本不兼容导致的,9.60.3版本中没有了armbat.dll。 解决办法: 1.在STEdgeAI \ 2.0 \ Projects \ STM32N6570-DK \ Applications \ NPU_Validation \ EWARM \ settings目录下打开Project.N6-DK.general.xcl文件。 2.将armbat.dll替换为armLibsupportUniversal.dll,并保存。 3.重新执行。
▲ 图12. 执行成功界面 Note:执行成功后,开发板不要断电,由于代码是运行在RAM中,断电会导致代码丢失,需要重新执行上面的步骤。 3.3. 评估基本性能 运行下面的脚本完成简单评估(路径自行替换):
▲ 图13. 网络基本信息 上图是网络运行的基本信息,包括输入输出的格式,运行AI的环境,上图13中显示了ST Neural ART(即STM32N6的NPU),MCU的频率,NPU的频率,Cache打开的情况等。
▲ 图14. 神经网络运行情况 上图14显示了神经网络的运行情况,运行了10次,运行次数由参数-b决定,推理时间平均为8.453ms。CPU Cycles这一簇有三列,第一列代表NPU的预配置花费的cycles,第二列代表NPU推理用的cycles,第三列代表NPU后处理用的cycles。其中第一和第三列是MCU参与的过程,所以可以理解为NPU在推理过程中占用了71.1%的负载。 3.4. 评估准确率 运行以下脚本,使用伪随机数据进行模型验证: Note:这里默认使用的是伪随机数据。
▲ 图15. 使用伪随机数据进行验证,生成报告 运行以下脚本,使用真实数据进行模型验证: Note:-vi表示真实的数据集,input_20_images.npy的shape为(20, 224, 224, 3),代表20张224x224x3的图片。
▲ 图16. 真实数据的验证报告 0 4 其他 4.1. 优化 在3.1节中,提到了两个默认的配置文件:neural_art.json和stm32n6.mpool,我们将其拷贝到当前的工作目录,并打开neural_art.json进行编辑,添加下面一项内容:
▲ 图17. neural_art.json 然后使用下面指令重新生成文件: 完成以后参考3.2,3.3小节的内容重新编译下载,并评估性能,该配置将提升性能。如下图18所示:
▲ 图18. 性能提升 在3.3小节中,单次推理平均时间为8.453ms,这里提升到了6.277ms,CPU cycles栏可以看到NPU的处理负载达到了99.8%,说明神经网络的推理几乎不需要MCU参与了。其主要优化选项为--enable-epoch-controller,意思是使能专门的硬件自动处理每个epoch之间NPU的预配置和后处理的工作,从图中可以看到epoch的数量明显减少了,这也是该选项的主要作用。目前ST官方发布的AI参考软件包,一般都使能了这个优化选项,如果没有使能,请使能后重新检查推理时间。 4.2. IO格式 在4.1节中,可以看到模型的输出为float32类型的数据,如下图19所示。
▲ 图19. 输出格式为float32 在应用层,有时候可能需要使用int8,ST的编译器支持直接输出int8,而不需要重新修改模型文件,只需要添加--output-data-type int8选项即可,如下:
▲ 图20. IO格式改变后 改变后从上图20可以看到,输出格式变为了int8,并且最后一个用于int8到float32转换的epoch被移除了。 另外,如果是Pytorch输出的ONNX格式的模型,通常是channel first格式,但嵌入式图像处理的Pipeline通常是channel last格式,我们只需要使用--inputs-ch-position chlast参数,ST的编译器会自动添加格式转化的layer到神经网络中,而不需要重新编译和生成channel last格式的模型。 0 5 总结 本文介绍了ST的AI编译器的基本使用,神经网络在STM32N6上的性能评估方法,以及相关的优化方法,ST的官方包通常会将这些选项和配置做默认选项,但用户也需要了解这些基本配置过程,以方便在实际使用过程中进行修改和调优。 |
【STM32N6570-DK评测】3.CubeMX关于DCMIPP和CSI的BUG整理及摄像头使用
线下培训(深圳) | 基于STM32N6的边缘人工智能应用开发实训
《STM32N6视频课程》学习笔记+STM32N6 系统资源隔离: RIF对外设的配置和管理
《STM32N6视频课程》学习笔记+STM32N6系统资源隔离— RIF访问规则与非法访问控制
《STM32N6视频课程》学习笔记+STM32N6 系统资源隔离 Cortex M55 TrustZone
《STM32N6视频课程》学习笔记+STM32N6 资源隔离RIF简介(一)
《STM32N6视频课程》学习笔记+STM32N6 密码学硬件以及安全存储
《STM32N6视频课程》学习笔记+STM32N6 安全启动与安全升级动手实验
《STM32N6视频课程》学习笔记+STM32N6 安全启动与安全升级
《STM32N6视频课程》学习笔记+STM32N6 BSEC 调试访问控制
 微信公众号
微信公众号
 手机版
手机版