|
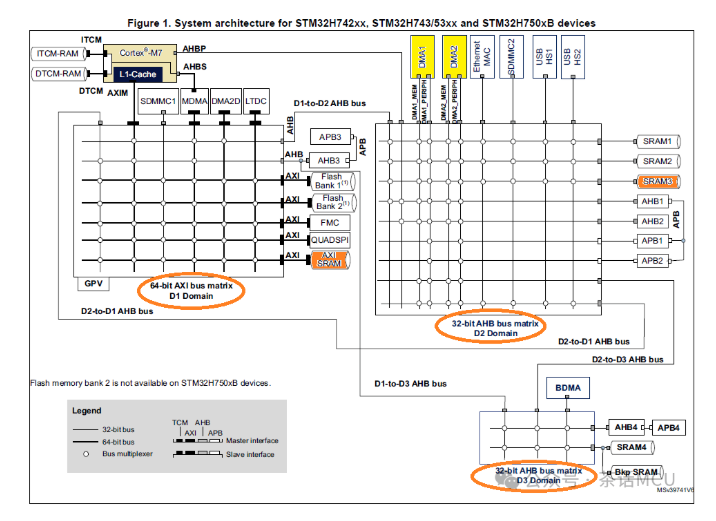
有人使用STM32H750的GPIO、TIMER和DMA读取外部 高速ADC模块时,发现有一个DMA通道的数据总是异常。 他的方案是这样的,GPIO连接ADC模块的数据端口,再通过DMA将数据传入MCU内部RAM。同时用TIM1输出120MHz频率的PWM波作为ADC模块的时钟信号,并作为主定时器触发同步启动TIM3产生的四路30MHz的PWM信号,并利用各路比较事件触发内部DMA。TIM1与TIM3构成主从同步启动关系。 可是他发现, 四路DMA采集的数据中,有一路DMA传输的采样结果总是异样,不论结果还是数据更新频率。他认为,如果是ADC采样不稳定,应该是4个通道都有相同表现才对,为什么只是一个通道有问题呢? 根据他提供的信息及相关工程配置进行了解,从方案及配置上讲没发现什么明显问题。 对于STM32H7系列,每个DMA请求可申请的stream是可以灵活调整的。现在他发现某个DMA stream有问题,便建议他尝试将DMA通道进行重新再配置,看看出问题的DMA stream是否固定地对应某个TIMER的请求。 下图是STM32H750/STM32H742,743,753系列芯片的内部系统框架
另外,他当前配置的DMA触发频率比较高,来自TIMER的DMA请求多而快。按照它目前的设计,TIMER3溢出频率为30MHz,且每个周期产生4个DMA请求,相当于每秒有120M个DMA请求!我担心DMA没法及时响应导致问题。 于是也建议他尝试将ADC和TIMER工作时钟逐步放低进行测试,比方80MHZ/20MHz甚至更低。 后来,他经过验证后进一步反馈,当把主定时器/从定时器的溢出频率调低,配置成60MHz/15MHz时所有的通道就都正常了。 这样看来,基本可以断定是TIMER的触发频率太快导致多通道的DMA响应竞争问题。我们不妨模拟咨询者的应用场景,来一起体验下多通道DMA响应竞争问题。 我使用STM32H743开发板,主频配置在480MHz,使用D2域的TIM3的4路比较事件产生DMA请求,让不同DMA通道将RAM数据相应地搬运到D3域GPIO A/B/C/D的四个管脚,实现电平翻转。TIM3使用内部240MHz时钟源。 下面是TIM3的基本配置,我将ARR固定为7,测试过程中只修改计数器分频值来调整TIMER的溢出频率,进而调整DMA请求触发频率。 令4个比较输出通道分别在计数器CNT=0,2,4,6四个位置时产生比较事件以申请相应DMA请求。(强调:后面测试过程中ARR始终为7)
下面测试分四种组合进行,即根据存放源数据所用RAM区域和用到DMA模块的个数形成四种组合。
其中,第1种、第2种组合,仅使用DMA1模块的4个传输通道,二者差别在于内存数据是放在D1域的AXI SRAM还是D2域的SRAM3。顺便声明下,测试过程中除了systick中断外没有开启其它任何可配置中断,包括DMA的。第1种和第2种组合都用下面DMA基本配置,传输方向都是从内存到外设,选择Circular模式。
四个DMA Stream的软件优先级都一样,差别就是硬件优先级,硬件默认编号低的优先级高。 我们调整TIM3的分频系数,从0开始逐步加大分频,直到四个翻转输出完全正常为止。所谓正常输出是指四个GPIO口输出跟触发频率同频、四路输出同时保持固定相位差的稳定输出。 先看第一组合【使用DMA1和D1域的AXI SRAM】的第一种情形。 下面波形是TIM3分频系数为0时的四路GPIO的翻转输出,从上往下依次对应DMA1-S1/S2/S3/S4的传输。此时TIM3的溢出频率为30MHz,每个周期产生4个DMA请求。此时,实际有输出的只有S1和S2,而S3/S4是没有输出的。
我们虽然可以看到S1、 S2两路比较规范的输出,我们可以借助仪器发现此时波形的翻转周期大概53ns,而此时TIM3的触发周期则为33ns,也就是说DMA的传输是跟不上此时的触发频率的,它只能按它此时最大的响应能力来实现传输。对于低优先级的S3、S4就丧失了实现传输的机会。打个比方,你使用网球发球机来练习,当你发球机发球速率超过你最大接球速率时,发球机再怎么提高发球速率,你的接球速率实际上是固定的,即使劲吃奶的力气可以完成的最大接球速率。 下面波形是TIM3分频系数为1即二分频时的四路GPIO的翻转输出,同样,从上往下依次对应DMA1-S1/S2/S3/S4的传输。此时TIM3的溢出频率为15MHz。
相比TIM3的溢出频率为30MHz时,这里多了1路GPIO输出,它是由DMA1-S3实现的。我们借助示波器可以看到。S1、S2实现的两路GPIO翻转是符合预期的,翻转周期大概66ns。S3实现的GPIO翻转就明显慢了,它只有在S1、S2有空闲时才能得到响应,此时S4因为自身最低优先级而没有得到响应的机会,仍无法正常实现GPIO翻转。 不妨再降低TIM3的触发频率。下面波形是TIM3分频系数为2即三分频时的四路GPIO的翻转输出,从上往下依次对应DMA1-S1/S2/S3/S4的传输。此时TIM3的溢出频率为10MHz。
此时,DMA1-S1/S2/S3的三路传输都是正常的,GPIO翻转周期也符合预期【声明下,这里说的翻转周期指GPIO翻转输出的高电平宽度或低电平宽度,即相邻两次翻转操作所对应的时间】,S4的传输倒是实现了,因为其相对最低优先级,只能在前面S1/S2/S3优先响应后才有机会得到响应,所以它的传输并不及时。不难猜测,如果将触发频率再降低些,4路DMA传输该有机会都能得到完全响应了。 下面波形是TIM3分频系数为3即四分频时的四路GPIO的翻转输出,此时TIM3的溢出频率为7.5MHz。到此,DMA1-S1/S2/S3/S4的传输都正常了,翻转周期、波形相差都正确。
显然,如果再降低TIM3的触发频率,DMA的传输就更加游刃有余,实现完美翻转自然没有问题。 下面来看第二种组合【使用DMA1和D2域的SRAM3】的各种情形,与上面的区别在于RAM使用D2域的SRAM3,其它条件一样。 同样,我们还是从TIM3分频系数为0开始。此时TIM3的溢出频率为30MHz,每个周期产生4个DMA请求。此时,实际有输出的只有S1、S2和S3,而S4没有实现输出。
其实,借助仪器测试,此时DMA1-S1输出最稳定,翻转周期也符合预期,S2 和S3的输出跟预期整体差不多,但不是很稳定,具体表现偶尔的翻转宽度不符合预期。S4因为优先级最低的原因,基本没有得到响应机会无法实现翻转。不过,相比从AXI SRAM取数据的同等配置,这里的结果要好得多。 下面是TIM3分频系数为1即二分频的输出情形。此时TIM3的溢出频率为15MHz,每个周期产生4个DMA请求。此时,四路输出已经完全正常了。不难看出,使用D2域的SRAM,同等条件下,比使用D1域的SRAM,DMA的传输效率要高得多。
下面波形是TIM3分频系数为2即三分频时的四路GPIO的翻转输出,此时TIM3的溢出频率为10MHz。刚才2分频时四路输出都正常,现在TIM3变为3分频了,DMA1-S1/S2/S3/S4的四路传输都正常就毫无悬念了。
我们接着看第三、第四中组合的各种情形,这两种组合共用下面的DMA配置,即DMA1和DMA2各提供两个传输通道来实现GPIO的翻转。
现在看第三组合【使用DMA1+DMA2和D1域的AXI SRAM】的第一种情形。 下面波形是TIM3分频系数为0时的四路GPIO的翻转输出,由DMA1-S1/S2和DMA2-S3/S4实现的。此时TIM3的溢出频率为30MHz,每个周期产生4个DMA请求。 虽然四路输出都有了,但翻转频率跟触发频率是对应不上的,正常来讲翻转周期应该是33ns,实际翻转周期大概是95ns的样子,明显慢于触发频率。从输出上看,虽做到了雨露均沾,实际输出在有些场合可能还是没法接受的。因为实际输出跟触发请求缺乏对应关系,不少DMA请求是丢掉了的。
当我把TIM3分频系数设置为1即进行二分频后,四路GPIO的翻转输出跟上面一样,每一路的实际翻转周期仍然是95ns样子。此时正常的翻转周期应该是66ns,显然翻转周期依然不符合预期。 当我把TIM3分频系数设置为2即进行三分频后,四路GPIO的翻转输出就完全正常了,即翻转周期、相差都符合预期。见下面输出波形图,此时翻转周期为100ns。
不言而喻,如果再降低TIM3触发频率的话,输出会更加没有问题。 现在开始看最后一种组合【使用DMA1+DMA2和D2域的 SRAM3】的各种情形。 同样,我们从TIM3分频系数为0开始进行测试。下面就是TIM3触发频率为30MHz,使用DMA1和DMA2从D2域SRAM3搬运数据到GPIO实现的输出波形,此时输出完全正常。
既然TIM3不做分频都能正常实现四路的输出,如果将TIM3做个2分频后再来触发,实现四路GPIO的正常翻转自然也不在话下,见下面输出波形图。
验证到这里,明显感觉到使用1个DMA和使用2个DMA模块的差别就太明显了,尤其在这种多请求高触发频率的场合。 我基于前面四种组合的全部验证结果做了如下统计表格,顺便分享出来供参考。 [下面表格中绿色代表输出完全符合预期,黄色表示虽有输出,但跟预期不符,比方只有部分通道实现输出,或者虽有输出,但实际参数与预期不符等】
表格分上下两部分,表格上半部分是使用两个DMA实现四路输出的情况,下半部分是使用1个DMA的情形。基于当前的测试场景,在其它同等条件下,使用双DMA的情形要远好于使用1个DMA的情形。 表格又可以分左右两部分,左半部分表示RAM使用D1 AXI SRAM的情况,右边表示RAM使用D2域的SRAM的情况。基于当前的测试场景,在其它同等条件下,使用D2 域RAM时要远好于使用D1域RAM的情形。 显然,在同一组合条件下,随着DMA请求的触发频率降低,DMA面临的压力就变小直至变得根本没压力。基于前面的测试,这里稍作总结,以供参考。 在使用DMA传输时,我们要注意它的响应速率也是有限的,具体跟总线时钟、总线宽度、总线繁忙度都有关; 在涉及到多通道DMA并发请求时,要注意不同DMA通道间是存在竞争的,低优先级的DMA通道可能不能得到及时响应甚至丧失响应; 涉及多通道DMA并发请求时,若有多个DMA模块的最好分模块安排,不必集中使用一个DMA模块; 采用DMA传输时,尽量选择最佳的DMA传输路线或方式,比方选择最合适的DMA模块,选择最合适的源端或目的端; 在资源有限而事件繁多的情况下,要综合考虑CPU和DMA的配合使用,不要忙的忙死,闲的闲死,让二者的工作形成互补而不是互为掣肘,最终实现整个芯片的最佳性能。 文章出处:茶话MCU |
经验分享 | 通过STM32 TIMER的PWM功能模拟输出正弦波
SPI 32位宽DMA方式收发失败问题
经验分享 | STM32N6 ADC DMA 传输失败案例分享
经验分享 | DMA发送函数只能第一次调用有效?
经验分享 | 使用EXIT0同步触发SPI的DMA发送话题
【开发经验】LAT1500 如何通过DMA配合CRC功能
我心中的ST中文论坛
经验分享 | 为什么重启ADC的DMA传输要先停掉ADC?
经验分享 | 使用GPIO+DMA+TIM模拟SPI通信演示
经验分享 | 为什么重启ADC的DMA传输要先停掉ADC?
 微信公众号
微信公众号
 手机版
手机版