.png) STMCU小助手
发布时间:2021-12-12 21:44
STMCU小助手
发布时间:2021-12-12 21:44
|
为了说清楚这个问题,我特意翻出了压箱底的那本杜春雷老师的《ARM体系结构与编程》,内容虽然是旧了点,但经典毕竟是经典,每次看都会有新的收获。 本来想把标题定为“xxx,看这篇就够了”,但因为功力不够,怕是误人子弟,担心最终只能成为标题党,毕竟这个话题涉及到计算机架构和存储系统。所以还是把标题改成了“例说STM32F7高速缓存——Cache一致性问题”。那么,就从应用的角度出发好了,从标题大概也可以看出,这篇文章的内容编排就是,先介绍高速缓存(俗称 Cache)的概念,再以具体的微控制器(STM32F769)为例进行探讨,最后引入一个例子进行分析,让大家深刻理解 Cache 一致性问题及其解决办法。 好了,废话不多说,开始吧! 1. Cache的基本概念和工作原理 1.1 为什么需要Cache 大概十年前,常用的微控制器的主频一般为几十 MHz,时至今日,上百 MHz 主频的 MCU 已经很常见了。比如,采用 ST 最新40nm工艺的 STM32H7 已经可以跑到 400 MHz 了,而一旦 ARM Cortex M7 发展到 28nm 技术,频率将达到 800 MHz。(想想就觉得好可怕,设备越来越智能了,好担心以后找不到敲代码的活了 >_<) 本文所使用的是基于 Cortex-M7 的 STM32F769I-DISCO 板,其主频高达 216 MHz。但仔细想想,虽然微控制器的频率大幅提高了,可是一般作为主存储器使用的动态存储器(DRAM),其存储周期仅为几十 ns。那么,如果指令和数据都存放在主存储中,主存储器的速度将会严重制约整个系统的性能。因此,高性能的微控制器会在主存储器和 CPU 之间增加高速缓冲存储器(Cache),目的是提高对存储器的平均访问速度,从而提高存储系统的性能。 通过引入 cache,存储系统的性能得到了很大的提高,但同时也带来了一些问题,比如,由于数据将存在于系统中不同的物理位置,可能造成数据的不一致性。 1.2 基本概念 时间局部性 和 空间局部性 高速缓冲存储器是全部用硬件来实现的,因此,它不仅对应用程序员是透明的,而且对系统程序员也是透明的。Cache 与主存储器之间以块(cache line)为单位进行数据交换。当 CPU 读取数据或者指令时,它同时将读取到的数据或者指令保存到一个 cache 块中。这样当 CPU 第2次需要读取相同的数据时,它可以从相应的 cache 块中得到相应的数据。因为 cache 的速度远远大于主存储器的速度,系统的整体性能就得到很大的提高。实际上,在程序中通常相邻的一段时间内 CPU 访问相同数据的概率是很大的,这种规律称为时间局部性。 不同系统中,cache 的块大小也是不同的。通常 cache 的块大小为几个字。这样当 CPU 从主存储器中读取一个字的数据时,它将会把主存储器中和 cache 块同样大小的数据读取到 cache 的一个块中。比如,如果 cache 的块大小为4个字,当CPU从主存储器中读取地址为 n 的字数据时,它同时将地址为 n、n+1、n+2、n+3 的4个字的数据读取到 cache 中的一个块中。这样,当 CPU 需要读取地址为 n、n+1、n+2 或者 n+3 的数据时,它可以从 cache 中得到该数据,系统的性能将得到很大的提高。实际上,在程序中,CPU 访问相邻的存储空间的数据的概率是很大的,这种规律称为空间局部性。 时间局部性和空间局部性保证了系统采用 cache 后,通常性能都能得到很大的提高,所以想要充分发挥 Cache 的作用,就要保证有比较高的命中率(Cache Hit)。 I-Cache 和 D-Cache 如果一个存储系统中指令预取时使用的 cache 和数据读写时使用的 cache 是各自独立的,这是称系统使用了独立的 cache,反之则为统一的 cache。其中,用于指令预取的 cache 称为指令 cache(I-Cache),用于数据读写的 cache 称为数据 cache(D-Cache)。使用独立的 I-Cache 和 D-Cache,可以在同一个时钟周期中读取指令和数据,而不需要双端口的 cache。但这时候,要注意保证指令和数据的一致性。 Cortex-M7 架构为我们配备了独立的高速指令缓存(I-Cache)和高速数据缓存(D-Cache)。 Cache line Cache 与主存储器之间以块(cache line)为单位进行数据交换,Cache 在逻辑上被划分为若干 cache line,对应着一组存储器的位置,因此,Cache 与主存储器交换数据的最小粒度就是 cache line。 Cache Hit 和 Cache Miss Cache命中(Cache Hit)——要访问的数据/指令已经存在缓存里; Cache缺失(Cache Miss)——要访问的数据/指令不在缓存里; 如果发生 cache miss 并且 cache 未满,则在 cache 中发现一个位置,并把新的缓存数据存到这个位置。如果 cache 已满,则要通过 cache 替换策略进行 cache line 的替换,腾出空闲的位置后,再将新的缓存数据存到这个位置。 Read-allocate 和 Write-allocate 根据不同的分配方式,可以把 cache 分为读操作分配(Read-allocate)cache 和写操作分配(Write-allocate)cache。 对于读操作分配 cache,当进行数据写操作时,如果 cache 未命中,只是简单地将数据写入主存中。只有在数据读取时,才进行 cache 内容预取。 对于写操作分配 cache,当进行数据写操作时,如果 cache 未命中,cache 系统将会进行 cache 内容预取,从主存中将相应的块读取到 cache 中相应的位置,并执行写操作,把数据写入到 cache 中。对于写通类型的 cache,数据将会同时被写入到主存中,对于写回类型的 cache 数据将在合适的时候写回到主存中。 由于写操作分配 cache 增加了 cache 内容预取的次数,它增加了写操作的开销,但同时可能提高 cache 的命中率,因此这种技术对于系统的整体性能的影响与程序中读操作和写操作数量有关。 读操作分配(Read-allocate)方式的简写为 RA,写操作分配(Write-allocate)方式的简写是 WA。 Write-back 和 Write-through 按 cache 中内容写回主存中的方式分类,可分为 Write-back 和 Write-through 两种方式。 Write-back(翻译为“写回”或“回写”)——写数据时,只更新缓存,然后将 cache line 标记为“dirty”,当这个缓存行被新的缓存行替换,或者手动 clean 的时候,再将数据写到存储器中。 Write-through(可能翻译为“写通”、“透写”或“直写”)——写数据时同时更新缓存和二级存储,缓存行不被标记为“dirty。这样,当某一个 cache line 需要替换时,就不必将其中的数据写到主存储器中去了,新调入的块可以立即把这一块覆盖掉。 回写(Write-back)方式的简写为 WB,透写(Write-through)方式的简写是 WT。 另外,Dirty 是标记那些需要写回到存储器中的缓存数据。当一个“dirty”的缓存行被新的缓存行替代时,就需要从缓存中移除一个缓存行(cache line),为新的数据腾位置,这个过程称为驱逐(Eviction)。 1.3 Cache的工作方式 Cache的工作原理 相信如果大家认真看了上面描述的基本概念后,大概也猜到 Cache 的工作流程,下面我们一起来理清一下吧。 
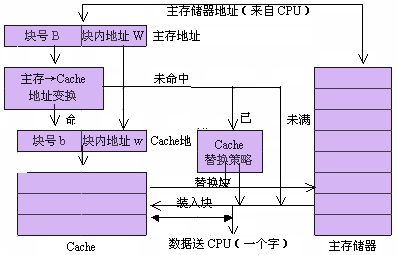
在 cache 存储系统中,把 cache 和主存储器都划分成相同大小的块。因此,主存地址可以由块号 B 和块内地址 W 两部分组成。同样,cache 的地址也可以由块号 b 和块内地址 w 两部分组成。 当 CPU 要访问 cache 时,CPU 送来主存地址,放到主存地址寄存器中。通过地址变换部件把主存地址中的块号 B 变换成 cache 的块号 b,并放到 cache 地址寄存器中。同时将主存地址中的块内地址 W 直接作为 cache 的块内地址 w 装入到 cache 地址寄存器中。如果变换成功(即 Cache 命中),就用得到的 cache 地址去访问 cache,从 cache 中取出数据送到 CPU 中。如果变换不成功,则产生 Cache 失效信息,并且用主存地址访问主存储器。从主存储器中读出一个字送往 CPU,同时,把包含被访问字在内的一整块都从主存储器读出来,装入到 cache 中去。这时,如果 cache 已经满了,则要采用某种 cache 替换策略把不常用的块先调出到主存储器中相应的块中,以便腾出空间来存放新调入的块。由于程序具有局部性特点,每次块失效时都把一块(由多个字组成)调入到 cache 中,能够提高 cache 的命中率。 Cache 的映射方式 上面我们提高,cache 中的块与主存储器中的块有一个地址转换关系,也就是 cache 的映射方式。 一般来说有如下几种映射方式: (1)全关联(full-associative)方式 【区块划分】将主存与 Cache 划分成若干个大小相等的块(lines)。 【映射关系】主存中任意一块都可以映射到 Cache 中的任意一块的位置上。 
如果 Cache 的块容量为 Cb,主存的块容量为 Mb,则主存和 cache 之间的映射关系共有 Cb * Mb 种。如果采用目录来存放这些映射关系,则目录表的容量为 Cb。 【优缺点】 优点:访问灵活,命中率高,Cache 存储空间利用率高,冲突率低,只有 Cache 满时才会出现在冲突。 缺点:地址变换比较复杂,每次都要与全部内容比较,速度相对慢,成本高,因而应用少。 【地址组成】 主存:块号 + 块内地址 缓存:块号 + 块内地址 
(2)直接映射(direct-mapping)方式 【区块划分】 将主存根据 Cache 的大小分成若干分区(主存的大小为 Cache 的整数倍),Cache 分成若干个相等的块(lines),主存的每个分区也分成与 Cache 相等的块。 【映射关系】 主存中的每一个分区由于大小与 Cache 完全相同,可以与整个 Cache 相像,每个分区中的每一块正好与 Cache 的每一块配对。也就是说,主存中一块只能映射到 Cache 中的一个特定的块,编号不一致的块是不能相互映射的。 
【优缺点】 优点:地址变换简单,只需检查区号是否相等即可,因而可以得到比较快的访问速度,硬件设备简单。 缺点:替换操作频繁,命中率比较低,每块相互对应,不够灵活。 【地址组成】 主存:区号 + 块号 + 块内地址 缓存:块号 + 块内地址 (3)组相联(set-associative)方式 【区块划分】 主存:主存根据 Cache 大小划分成若干个区,每个区内划分成若干个组(sets),每个组再划分成若干个块(lines)。 Cache:划分成若干个组(sets),每个组划分成若干个块(lines)。 【映射关系】 从主存的组到 Cache 的组之间采用直接映射方式,当主存中的一组与 Cache 中的一组之间建立了直接映射关系之后,在两个对应的组内部采用全关联映射方式。 【优缺点】 融合了直接映射与全关联映射两种映射方式,结合了两者的优点。具体实现容易,命中率与全关联映射接近。 【地址组成】 主存:区号 + 组号 + 块号 + 块内地址 缓存:组号 + 块号 + 块内地址 实际上,现代的 CPU 或者 MCU,绝大多数都是采用组相联的 cache 映射方式。 1.4 存储系统的一致性问题 当存储系统中引入了 cache 时,同一地址单元的数据可能在系统中有多个副本,分别保存在cache、写缓冲区和主存中。如果系统采用了独立的数据 cache 和指令 cache,同一地址单元的数据还可能在数据 cache 和指令 cache 中有不同的版本。位于不同物理位置的同一地址单元的数据可能会不同,使得数据读操作可能得到的不是系统中“最新的”数值,这样就带来了存储系统中数据的一致性问题。 在 ARM 存储系统体系中,数据不一致的问题有一些是通过存储系统自动保证的,另外一些数据不一致的问题则需要通过程序设计时遵守一定的规则来保证。 (1)地址映射关系变化造成的数据不一致 当系统中使用了 MMU 时,就建立了虚拟地址到物理地址的映射关系。如果查询 cache 时进行的相联比较使用的是虚拟地址,则当系统中虚拟地址到物理地址的映射关系发生变化时,可能造成 cache 中数据和主存中数据不一致的情况。 (2)指令 cache 的数据一致性问题 当系统中采用独立的数据 cache 和指令 cache 时,一些操作序列可能造成指令不一致的情况。 (3)DMA 造成的数据不一致问题 DMA 操作直接访问主存,而不会更新 cache 和写缓冲区中相应的内容,这样就可能造成数据的不一致。 如果 DMA 从主存中读取的数据已经包含在 cache 中,而且 cache 中对应的数据已经被更新,这样 DMA 读到的将不是系统中最新的数据。同样,DMA 写操作直接更新主存中的数据,如果该数据已经包含在 cache 中,则 cache 中的数据将会比主存中对应的数据“老”,也将造成数据不一致。 为了避免这种数据不一致的情况的发生,根据系统的具体情况,执行下面的操作序列中的一种或几种。 将 DMA 访问的存储区域设置成非缓冲的(uncachable 及 unbufferable); 将 DMA 访问的存储区域所涉及的数据 cache 中的块设置为无效,或者清空数据 cache; 清空写缓冲区(执行写缓冲区中延迟的所有写操作); 在 DMA 操作期间限制处理器访问 DMA 所访问的存储区域。 |

STM32F745 USART1 Bootloader启动失败排查与解决的流程分析
STM32芯片命名规则
STM32 引脚到底有多少?为什么一个引脚能当好几个用?
入门嵌入式,为什么STM32是“优选起步”?
嵌入式-单片机-STM32 EXTI中断
STM32单片机进行除零运算,为何程序不崩溃?
STM32 LL为什么比HAL高效?
STM32时钟详解
2025国庆中秋活动体验报告2——TouchGFX的UI设计
2025国庆中秋活动体验报告1——TouchGFX环境配置
 微信公众号
微信公众号
 手机版
手机版