.png) STMCU小助手
发布时间:2022-11-12 15:15
STMCU小助手
发布时间:2022-11-12 15:15
|
引言 本应用笔记与 STM32U575/585 微控制器(MCU)中嵌入的通用 DMA(GPDMA)相关。GPDMA 是一种系统外设,是 AHB 总线上的双端口主设备。它被用于通过链表在外设和/或存储器之间传输数据。所有 GPDMA 可编程传输均在系统层面提供更高性能,并使 CPU 无需执行这些数据传输任务。 本文档的目的不是将现有的 GPDMA 专用章节重新编写到产品参考手册中,而是为系统开发人员提供一些以性能为导向的编程指南。 本文档以 GPDMA 和可能受到 GPDMA 协助的外设的组合功能为基础。本文档聚焦于为了优化系统性能和满足应用要求而需要考虑的所有关键点。 本应用笔记包含关于以下内容的原理阐述和建议:% l- Z \2 I$ j4 D# k2 C • GPDMA 通道分配 • GPDMA 端口分配 – 对于始于存储器映射源位置的传输+ H O$ F2 P% d% X – 对于止于存储器映射目标位置的传输( N6 l1 n+ \# l • GPDMA 传输优先级分配4 _; V6 h- S; s3 c- } • GPDMA 源/目标突发编程,包含数据宽度和突发长度" R: a. a1 ?: y2 Q6 v & A* d3 E$ _- C, I* P' w 1 概述1 a8 E* ~; |. t M- ^4 Z I 本应用笔记适用于 STM32U575/585 微控制器,这些微控制器是基于 Arm® Cortex®核心的器件。8 ^; J9 r; T. w0 C 提示 Arm 是 Arm Limited(或其子公司)在美国和/或其他地区的注册商标。 参考文档 • 参考手册基于 Arm®的 STM32U575/585 32 位 MCU(RM0456) • STM32U585xx 数据手册(DS13086) • STM32U575xx 数据手册(DS13737) - M! @# e P2 |/ W$ W 2 GPDMA 通用指南! X# d& [) y# g 2.1 GPDMA 概述 在减载 CPU 的控制下,GPDMA 控制器通过链表执行存储器映射外设和/或存储器之间的可编程数据传输。& }6 \4 K/ f/ h GPDMA 是双端口 AHB 主设备和系统外设。大多数外设和存储器都与之建立连接。在需要数据传输时,这一点提供了很大的灵活性并提高了系统性能。链表是存储器中程序化的数据结构,旨在让每个 GPDMA 通道为链接和安排DMA 数据传输做好准备。GPDMA 有 16 个通道。# |) {; U: e! q, F H& m% t7 ~5 I+ }+ b 2.2 GPDMA 通道分配6 }- q% ~8 M+ v, `4 h 用户必须分配一个通道用于 GPDMA 传输。为了能够同时处理来自源的 GPDMA 传输(读访问)和到达目标的GPDMA 传输(写访问),GPDMA 对给定 GPDMA 通道使用专用 FIFO。 FIFO 单元的单位是一个字节。FIFO 的大小决定了通道能够有效处理的最大 DMA 突发大小(突发长度与数据宽度的乘积)。注意,通常突发越大,系统总体性能越好:更高吞吐率/带宽传输,更低系统总线占用率。鉴于系统总线为 32 位字宽,建议将 DMA 源/目标数据宽度设定为 32 位(GPDMA_CxTR1 中的 S/DDW_LOG2[1:0]),以便最大限度减少总线使用量。6 c$ L/ ^9 M, ?, [ 如下表所示,有两类通道,分别具有不同的 FIFO 大小和寻址模式: • 通道 0 至 11:) D" M E. w: I- E2 n6 E: A, W( t – FIFO 大小为 8 字节(2 字)。 – 寻址限于线性模式:固定寻址(通常用于外设寄存器访问)或连续数据增量寻址(通常用于存储器访问)。 • 通道 12 至 15: – FIFO 大小为 32 字节(8 字)。0 Q y8 G$ U, I; z' \ v – 支持线性和二维寻址模式:二者均适用于源和目标,可设定两个地址跳转/偏移量:4 y ?2 l6 M3 @; O0 f4 X& Z* V ◦ 每个编程突发后 ◦ 每个编程块后 - c$ U: G; D$ p) B6 v" ? ![6WF$OVXLSO3Z3JXR]4VNR8G.png](data/attachment/forum/202211/12/152118ge994pdpdy5ho2bp.png "6WF$OVXLSO3Z3JXR]4VNR8G.png")
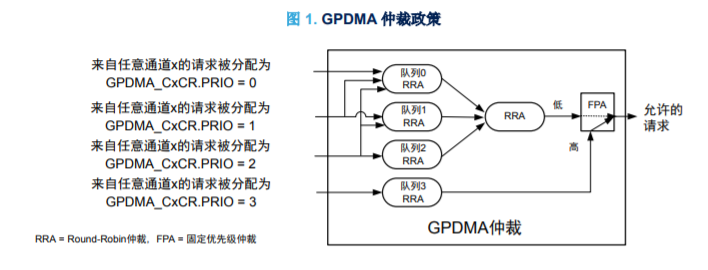
建议将通道 0 至 11 分配用于从 AHB/APB 外设到 SRAM 的传输或从 SRAM 到 AHB/APB 外设的传输,除非存储器需要二维寻址或外设是支持突发请求的 AHB 外设。然后,建议将突发设定为 1 字(FIFO 大小的一半),除非应用需要处理 8 或 16 位数据宽度。+ B h& {* M# h4 e1 K 建议将通道 12 至 15 分配用于存储器之间的传输。然后,出于性能方面的考虑,建议将突发设定为默认的 4 字(FIFO 大小的一半)。+ U L& ]1 d d4 V% l+ l* R 同样地,将通道 12 至 15 优先用于始于支持突发请求的 AHB 外设,比如 OCTOSPI、HASH 和 ADC。然后,通常将始于/止于外设的半传输设定为突发。建议将始于/止于存储器的(半)传输设定为 4 字突发。 对于具有更高带宽要求的 AHB 外设的始于/止于一些外设的传输,同样优先选择通道 12 至 15。建议将始于/止于存储器的(半)传输也设定为 4 字突发。 2.3 GPDMA 端口选择 用户必须为始于源(GPDMA_CxTR1 中的 SAP)的传输分配一个端口,并且为止于目标(GPDMA_CxTR1 中的DAP)的传输分配一个端口。在执行下一次数据传输之前,会通过下一个链表项和数据结构动态更新此分配。 ! n; j- T" G; v 关于 GPDMA 的总线拓扑可总结如下(参见第 4 节 了解更多信息):0 c) H7 P) h2 B# ~4 a6 O • GPDMA 端口 0 直接连接到 APB1 和 APB2 外设,不穿过 AHB 矩阵(参见图 2 和图 4)。/ w w5 a% }( l& [ • AHB 矩阵的默认从设备(参见图 2 和第 4.3.2 节 )为: – GPDMA 端口 0 的 AHB1 外设(MDF、FMAC 和 CORDIC) – GPDMA 端口 1 的 SRAM1 建议按照以下方式使用 GPDMA 的两个主设备端口:2 X+ x- r7 l4 w • 将端口 0 分配用于始于/止于外设的(半)传输,无论是 AHB 还是 APB 外设。将端口 1 分配用于其他(半)传输(分别止于/始于存储器)。对于 APB1 和 APB2 外设,端口 0 避免穿过互连矩阵,减少了相应通道上的总体延迟。这也减少了互连总线矩阵包含的和之后的 AHB 总线活动。 • 端口 1 被分配用于存储器至存储器的传输(特别是访问 SRAM1 时,但不仅限于此)。对外设使用端口 0 并对任何存储器使用端口 1 的优势在于:) X- ~5 H- S- } – 外设至存储器和存储器至外设的传输过程中两个端口上的带宽平衡 – 避免至存储器的突发直接影响外设访问的延迟 这是针对性能的典型和推荐配置。当然,用户可以自由地选择任何可以访问源位置的端口,以及任何可以访问目标位置的端口。 当通道未激活时,GPDMA 为加载下一个链表项而分配的链接端口由用户在通道层面进行定义(GPDMA_CxCR 中的 LAP)。下一个链接列表项已准备就绪并存储在内存中。然后,建议将端口 1 分配用于加载下一个链表项。% k0 k; F8 B. ? ' f$ {* N* u5 n$ ~ 2.4 GPDMA 通道优先级! H( E5 t( O7 x6 k. u$ n' U 为每个(半)传输分配一个优先级值,用来与其他并发传输进行竞争,从而使 GPDMA 仲裁器能够在一个主设备端口上允许(半)传输并为其安排时间。在用户层面,当通道未激活时,通过 GPDMA_CxCR 中的 PRIO[1:0]在通道层面对此进行准备。+ g4 ^# Z- G$ {: M" g0 `, k GPDMA 有两个用于实现 AHB 传输并行化的主设备端口。可通过这两个端口进行同步传输。每个端口发生的GPDMA 仲裁如下:& `& t0 W- \3 B8 W+ J" C' C1 f • 16 个可能请求的基于 FIFO 的读取突发之间基于优先级的仲裁(参见图 1) • 16 个可能请求的基于 FIFO 的写入突发之间基于优先级的仲裁(参见图 1)$ @6 S9 z' i1 a& Y" X! [! c • 读取和写入之间最终的 Round-Robin 仲裁阶段1 F" ^ F% ^. w' z8 \2 u GPDMA 仲裁阶段可能会为 GPDMA 引入 1 个周期的时钟延迟,以便在分配的主端口上生成允许突发的 AHB 地址(参见第 2.5 节 了解更多信息)。 GPDMA 实现可编程仲裁逻辑,使用户能够根据下列规则调整通道带宽和延迟:. F+ C/ }& G$ R2 X • 请求的突发传输的优先级可设定为 0 至 3。 • 用 Round-Robin 仲裁方案处理具有相同优先级的请求。 • 对于时效性的请求,建议使用优先级 3,因为它用高于 优先级 0 至 2 的固定较高优先级进行处理。 • 对非时效性通道实施加权 Round-Robin 分配,剩余带宽由优先级为 0 至 2 的请求共享。 • 不同的权重源自于设定的通道优先级并呈单调性变化,队列 0 的权重最低。- E$ w3 l9 q% c Q1 z ![X]98T$H@~{77KF`1BEDSJ_0.png](data/attachment/forum/202211/12/152118u9dr1am92f9v3fhr.png "X]98T$H@~{77KF`1BEDSJ_0.png")
- N6 i7 `* f6 K* |" c# `/ [ 用户需要为外设/存储器连接的 GPDMA 通道分配正确的优先级,才能使该通道达到合格的服务质量:$ j- ~( }& i% ]* v • 外设端无时序错误(无外设寄存器下溢/上溢)% L+ b3 Q6 p1 }# @, j; ]; U • 数据传输请求与此请求的履行之间的延迟可接受 • 对其他通道服务质量的影响可接受 为了满足应用的时序要求,必须谨慎地分配通道优先级。请求的基于 FIFO 的优先级 0 到 2 的传输,已准备好在主端口上再次调度,可能会因交换机的轮循机制仲裁服务器而延迟,并且执行最多 15 个优先级为 0 到 2 的并发(单/突发)传输。这种请求也是任何时间敏感的请求所抢占的第一个请求。6 T+ b/ y+ ]% t) B! ?0 X0 { 使用来自关键定时器的请求映射的 GPDMA 通道通常会被分配给时效性队列,因此能以最低延迟更新相关的TIMER 寄存器。相关人员可以为来自其他外设的 GPDMA 请求分配优先级 2 或 1,最后可以为存储器至存储器的传输分配最低优先级 0(尽最大努力流量)。通常可以为映射到通道 12 至 15 并具有突发功能的外设分配中间优先级1。 为了满足具体的应用要求,可对这一关于通道优先级的建议进行调整(参见产品参考手册了解更多关于仲裁和优先级的信息)。# x" V2 r/ n8 J2 U/ X8 J, g( K: } 对于给定通道,在链表层面执行数据传输。通过在存储器中使用设定的链表数据结构,用户可以将数据传输与同一通道的下一次数据传输串连起来。在给定链表项(LLI)的数据传输完成后,在执行下一次数据传输之前,GPDMA自动读取/提取下一个链表数据结构,并进行内部的寄存器更新。与数据传输一样,链接传输优先级由其通道的分配优先级给出。链接传输包含一系列的 32 位单次读取(通道 0 至 11 最多 6 次单次读取,通道 12 至 15 最多 8 次单次读取)。在 LLI 更新的每个 32 位读取之间,GPDMA 需要一个额外的时钟周期用于仲裁阶段。 r* \# u( l) v 2.5 GPDMA 突发; ?# d' s7 M. U( U M U: O9 s) K 初步设定的数据传输为 GPDMA 突发(从源读取的数据的突发或写入目标的数据的突发),通过以下参数进行定义: • 设定的数据宽度:8、16 或 32 位(通过 GPDMA_CxTR1 中的 S/DDW_LOG2[1:0])1 g5 m6 b! M/ m. N- W* h9 N6 D • 设定的突发长度:1 至 64(通过 GPDMA_CxTR1 中的 S/DBL_1[5:0]) 可以分别为源和目标设定突发大小。 突发是一系列节拍(n = 1 至 64)。每一拍是一次数据传输,具有相同数据宽度。例如,4 字突发是四个 32 位字的突发。突发长度为 1 的突发称为单次。 GPDMA 发布具有设定数据宽度的节拍:GPDMA 实施永远不会修改设定数据宽度。+ _* s( S3 W* u/ I W GPDMA 并非总是在分配的 AHB 主设备端口上发布具有设定突发长度的突发。在硬件中以下列方式之一实现GPDMA 突发: • 在分配的主端口上具有相同的 AHB 事务 • 当下列条件中的任何一个成立时,通过一系列长度更小的突发和/或单次: – 突发大小 > FIFO 大小的一半。 – 块大小(定义为源块大小)不是源数据宽度的倍数。% h7 ] N/ q0 ^( H5 K – AHB 限制: ◦ 在 1 KB 地址边界交叉点上6 F5 N/ ?( r- ~6 x ◦ 突发必须是 4、8 或 16 拍的增量突发0 ?$ E! S' \$ G9 t8 y' G. K* F GPDMA 实施保证数据完整性(相比于编程寻址),并通过实现最大允许突发大小(相比于编程突发)使性能最大化。1 S+ X4 m. t6 E( {2 v& H 建议将 GPDMA 突发的大小设定为所分配 GPDMA 通道的 FIFO 大小的一半(通道 0 至 11 通常为 1 字突发,通道12 至 15 通常为 4 字突发)。 6 @" y/ W0 X: [ l8 k 

+ K3 `: A+ V6 z" S GPDMA 突发是数据的基本块,位于固定地址或连续递增地址。对于通道 12 至 15(支持二维寻址),可在突发后执行第一次地址跳转。为了获得存储器中的二维缓冲区,用户可能必须设定不同于典型 4 字突发的突发。GPDMA实现自动优化性能,并包含此设定限制。& I5 r, T9 F8 i 在每个设定突发之前增加一个 GPDMA 仲裁时钟周期,前提是此突发大小小于 FIFO 大小的一半。每次数据传输既可以是单次数据传输(在每次 AHB 总线主设备上必须发送数据时执行数据仲裁),也可以组合成突发数据传输以便背靠背发送少量数据,在 GPDMA 单次仲裁阶段后不可能发生任何 GPDMA 抢占。这样可以最大限度缩短数据传输时间(总体延迟),并使吞吐率和总线效率最大化。0 b/ ]3 Q _" F, c* F6 ^. @ 考虑突发(包含多个节拍/数据)的传输的主要优势如下: • 将 GPDMA 仲裁缩减到只有一个阶段,该阶段适用于按突发大小定义的所有数据。 • 突发在 GPDMA(仲裁)层面不可中断,前提是其大小小于 FIFO 大小的一半。一组一定数量的读取/写入数据的延迟缩短,可更早完成传输(第一拍除外)。 • 如果面向的源或目标是内部存储器,则通过 AHB 总线上的增量 AHB 突发来实现设定的寻址增量突发。这样消耗的总线周期更少,还释放了总线带宽用于其他可能的并发主设备,或者能够为给定流量/带宽设定更低的总线频率。' c/ m: }& k+ o/ r7 W0 g e8 R • 如果面向的源或目标是位于固定地址并支持突发的外设寄存器(具有 FIFO 机制,如 ADC1、OCTOSPI 或哈希),由于发生过一次仲裁周期处罚,因此设定 GPDMA 4 字固定突发(在 GPDMA 仲裁后被分割成四个单次传输,以便与 AHB 兼容)以提高背靠背传输吞吐率。 如果 GPDMA 突发具有 AHB 突发事务,则在执行时,会增加分配的同一 AHB 主设备端口上的其他并发 GPDMA传输的延迟。在这段时间内,同一 GPDMA 端口上 GPDMA 请求的所有其他传输均挂起(以及所有其他计划从同一目标外设/存储器读取数据或向其写入数据的主设备)。建议通过设定通道优先级来管理不同应用要求,如第 2.4 节 所述。8 W; E, j* z$ N3 f2 e ~; b 7 Q: W! Q7 a' k0 }3 e 完整版请查看:附件5 E% ]2 h: h, f+ L 2 o7 }4 Q1 x4 }: n, i |

zh.DM00756700.pdf
下载650.66 KB, 下载次数: 2
|
U5性能是真不错 |
STM32U5低功耗测试
STM32怎么选型
内存配置的艺术:STM32为嵌入式系统高端UI优化RAM和闪存的三大策略
STM32U5 系列使用 LPBAM 进行功耗优化
【STM32U545】实现CAN数据收发
【我的STM32U5 项目秀】+04-MPU6050在STM32U5上的移植
实战经验 | 基于 STM32U5 创建 USBx_CustomHID 通信
STM32U5 x E-BIKE,记录你的骑行多巴胺
基于STM32U5系列TIMER+DMA+DAC应用经验分享
实战经验 | 基于 STM32U5 片内温度传感器正确测算温度
 微信公众号
微信公众号
 手机版
手机版