STMCU-管管
发布时间:2026-4-22 08:13
STMCU-管管
发布时间:2026-4-22 08:13
|
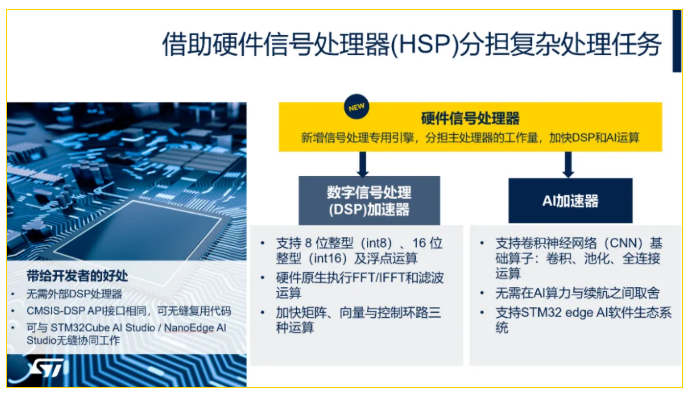
意法半导体全新硬件信号处理器(HSP,Hardware Signal Processor)是一颗专为本地处理优化的高性能、低功耗、低成本的协处理器,作为专用加速引擎,HSP可显著分担CPU负载,并大幅提升数字信号处理(DSP)与人工智能(AI)的运算性能。
这款创新硬件单元未来将集成到多款STM32微控制器,支持矩阵、向量、控制环路及数字信号处理等运算,无需外挂专用DSP芯片。首款搭载HSP的STM32U3B5/C5系列器件(配备2MB闪存)已正式推出,为超低功耗MCU带来运算性能的跨越式升级,让边缘端的高算力需求不再受功耗限制。 作为专为STM32打造的硬件加速单元,HSP可高效加速傅里叶变换等各类核心运算,且相比传统DSP,实现了零外接设备、零复杂配置的便捷体验。依托意法半导体成熟的硬件抽象层,开发者仅需调用少量API接口,即可快速启用HSP的加速能力,让低功耗器件轻松迸发超强运算性能——在部分应用场景下,搭载HSP的STM32U3,运算速度可达标准Cortex-M33器件的13倍! 超低功耗系统 为何纷纷放弃外置DSP? 在很多超低功耗应用场景中,外置DSP本是弥补算力不足的常用选择,却始终未能成为工程师的最优解,核心根源既在于低功耗与高算力的天然矛盾,也源于外置DSP本身的应用痛点。 超低功耗与高端传感应用的两难权衡 工程师为追求超低功耗或削减物料清单成本,往往不得不在性能方面做出重大妥协,这无疑会错失不少应用场景开发的可能性。比如振动、加速度监测这类工业传感应用,通常需要通过时域/频域分析,而这一过程需要强大算力支撑实数或复数快速傅里叶变换(FFT)运算。 但在传统超低功耗MCU上执行这类运算,成本往往高到难以承受:要么运算耗时过长、发热严重;要么只能额外搭配外置DSP,这会直接推高整体方案成本。最终,工程师只能舍弃部分功能,或重新选型、更换整套物料方案。
▲ STM32U3是首个搭载意法半导体 硬件信号处理器(HSP)的STM32产品系列 外置DSP的应用挑战 即便抛开成本问题,外置DSP的开发编程本身就是一道高技术门槛。尽管这类协处理器具备开放性,可适配多类应用场景,但实际开发过程复杂且成本高昂,对工程师的专业能力要求极高。DSP编程需要工程师反复迭代固件版本,才能让代码达到成熟、稳定、优化的状态。此外,这类代码通常不具备可移植性。工程师要么只能长期选用同一款外置DSP,严重限制物料清单的灵活性;要么每次换型都从零开始开发,不仅成本高、耗时长,还会挫伤开发积极性。 显而易见,外置DSP还会大幅增加系统复杂度。例如,设计人员在进行PCB布局时,需要处理更多的潜在故障点、考量更多走线与无源元件的适配;且外置DSP的开发多需从底层入手,配套工具与图形用户界面(GUI)十分匮乏。市面上也鲜有社区维护的开发环境,缺乏通用工具与接口来支持代码调试、硬件配置,以及内存或CPU占用监控。以音频DSP开发为例,企业往往需要投入数年时间才能完成开发并推出相关产品。对众多中小企业而言,这样的开发周期与成本难以承受。 全新HSP技术 重新定义超低功耗MCU算力 意法半导体内部多维度基准测试证实,HSP不仅能高效加速数字信号处理,更能大幅提升神经网络算法运行效率,在性能、能效、灵活性等方面均展现出颠覆性优势,让STM32U3成为超低功耗领域的算力标杆。
性能是传统Cortex-M33的13倍 针对传感应用中高频使用的傅里叶变换算法,HSP展现出极致加速能力:在256个采样点的测试中,无论是32位定点/浮点复数快速傅里叶变换,还是32位定点实数快速傅里叶变换,HSP的性能均达到传统Cortex-M33的13倍,完美适配工业振动监测、加速度检测等场景的运算需求。 能效是STM32U5的9倍 搭载HSP的STM32U3,与同架构的STM32器件相比,能效优势显著:较STM32U5提升至9倍,较未搭载HSP的STM32U3提升至3倍。HSP虽略微增加器件绝对功耗,但凭借超高速运算能力,大幅缩短运算时间,最终实现整体能耗降低,部分边缘AI应用的能效甚至能提升一倍,真正做到“算力升级,功耗不涨”。 性能是搭载MVE向量扩展的Cortex-M55的3倍 即便与竞品中搭载M型架构向量扩展(MVE,Helium)的Cortex-M55内核相比,STM32U3的HSP依旧表现亮眼:在相同算法测试中,性能达到其3倍。这意味着开发者无需选用成本更高、功耗更大的MCU,仅凭借STM32U3,就能获得更强性能、更优能效的硬件平台,大幅降低边缘端产品的设计和物料成本。 性能较采用TensorFlow Lite的Cortex-M33提升9倍 HSP的能力远不止于信号处理!研发团队发现,这款硬件单元能显著加速神经网络算法,尤其在STM32U3上表现突出。在关键词唤醒、图像分类、视觉唤醒词等典型算法上,全新HSP相较于采用TensorFlow Lite模型的Cortex-M33 MCU提升6~9倍;与相同内核并搭配STM32Cube AI Studio的STM32 MCU相比提升3倍。 这一突破将改变边缘AI的开发方式,为此,我们同步升级了软件工具链,以支持这款新型HSP的加速能力。那些原本无法运行边缘AI的超低功耗器件,如今有了可行方案。 开发灵活便捷,零门槛复用代码 HSP与STM32Cube AI Studio深度集成,简便易用,开发者只需使用ST硬件抽象层,即可自动调用HSP功能;同时,它还兼容CMSIS-DSP API接口,代码可直接复用到未来所有搭载HSP的STM32 MCU上,大幅提升开发效率,让开发者轻松拥有DSP级算力,却无需面对传统DSP的开发难题。 结语 HSP首发搭载到STM32U3B5/3C5系列,为超低功耗MCU打开了高算力、边缘AI的全新应用空间。未来,意法半导体将逐步把HSP扩展至更多STM32 MCU系列,让更多开发者享受到“低功耗+高算力+易开发”的三重优势。从工业传感到智能物联网,从边缘AI到无电池设备,STM32U3+HSP的超强组合,正以硬核运算能力打破性能与功耗的边界,为嵌入式开发带来更多创新可能! STM32U3新品板卡免费申请来了:
|

【stm32U3测评】FDCAN 满载性能实测
【STM32U3 评测】CAN FD测试与UDS OTA升级
【STM32U3 评测】基于 CAN 的 UDS OTA 不完全实现指南
【STM32U3评测】轻量级人脸检测部署。
【STM32U3 评测】FDCAN 性能极限与软硬件协同开发实测
【STM32U3评测】基于 HSP 的轻量级人脸检测部署
【STM32U3评测】低功耗模式功耗测量
【STM32U3评测】低功耗模式功耗测量
【stm32U3测评】使用FDCAN进行IAP升级----【1】Bootloader的实现
【STM32U3评测】CAN负载能力测试
 微信公众号
微信公众号
 手机版
手机版